이 보고서는 "NICE: CVPR 2023 Challenge on Zero-shot Image Captioning"라는 제목으로, Taehoon Kim 외 41명이 2023년에 발표했습니다.
Abstract
이 논문의 주요 내용을 요약하면 다음과 같습니다:
- 프로젝트 목표
- 컴퓨터 비전 커뮤니티에 이미지 캡셔닝 모델의 정확성과 공정성 향상 도전
- 다양한 시각적 개념을 다루는 새로운 평가 데이터셋 개발
- 챌린지 방식
- 특정 훈련 데이터 없이 제로샷(zero-shot) 챌린지 진행
- 모델들이 훈련 중 보지 못한 새로운 유형의 이미지 설명 생성 능력 테스트
- 챌린지 구성 요소
- 다양한 도메인의 시각적 개념을 포함하는 NICE 데이터셋 생성
- 혁신적인 이미지 캡셔닝 모델 평가 방법 개발
- 보지 못한 이미지 유형에 대한 설명 생성 능력 평가
- 기대 성과
- 비전-언어 AI 모델의 발전에 기여
- 이미지 캡셔닝 기술의 견고성과 적응력 향상
- 컴퓨터 비전의 제로샷 학습 한계 극복
- 의의
- 현재 이미지 캡셔닝 접근 방식의 한계 극복
- 다양하고 익숙하지 않은 시각적 콘텐츠 처리 능력 향상
- 더욱 유연하고 일반화된 AI 비전 모델 개발 촉진
1. Introduction
이 내용은 제로샷 이미지 캡셔닝의 학술적, 기술적 도전과 NICE 프로젝트의 혁신적 접근법을 소개합니다.
- 제로샷 이미지 캡셔닝의 정의와 의의
- 비전-언어 모델이 반드시 숙달해야 할 핵심 과제
- 장면에 대한 시각적 이해와 자연어 설명 능력 동시 요구
- real-world 응용 분야:
- 자연어 기반 이미지 검색 개선
- 웹상 부적절한 콘텐츠 감지
- 시각장애인을 위한 시각적 콘텐츠 설명
- 기존 이미지 캡셔닝 모델의 한계
- 초기 모델: 특정 데이터셋 내 훈련 및 테스트
- 새로운 개념 인식 및 설명에 제한적
- 미지의 카테고리 이미지 처리 능력 부족
- NICE 챌린지의 혁신
- 26,000개 이미지와 고품질 캡션으로 구성된 새로운 데이터셋 제공
- 특정 훈련 데이터 미제공으로 제로샷 능력 강제
- 챌린지 참여 현황:
- 검증 단계: 51개 팀 참가
- 테스트 단계: 31개 팀 참가
- 상위 팀 간 점수 차이 미미
- 데이터셋 평가 기준
- 데이터셋 규모의 중요성
- 다양한 카테고리 필수
- ground truth 캡션의 정확성과 고품질 보장
- 보고서의 구성
- 챌린지 세부 정보
- 평가 방법
- 결과
- 상위 참가팀의 접근 방식 소개
이 설명은 이미지 캡셔닝 기술의 현재 한계를 지적하고, 새로운 데이터셋과 챌린지를 통해 AI 모델의 일반화 능력을 향상시키려는 연구팀의 목표와 방법론을 상세히 설명하고 있습니다.
2. Challenge
이 내용은 NICE 챌린지의 핵심 구성 요소와 목적을 소개하는 챌린지 섹션입니다.
- NICE 데이터셋 특징
- 연구팀이 새롭게 큐레이션한 데이터셋
- 공개적으로 제공된 데이터셋
- 이미지 캡셔닝 능력 평가를 위한 목적
- 챌린지의 주요 구성 요소
- 데이터셋 소개
- 평가 방법론
- 챌린지 진행 단계
- 최종 결과 분석
- 챌린지의 핵심 목표
- AI 모델의 이미지 캡셔닝 능력 객관적 평가
이 섹션은 NICE 챌린지의 전반적인 접근 방식과 평가 프레임워크를 체계적으로 설명하고 있습니다.
2-1. Dataset

이 내용은 NICE 챌린지의 데이터셋에 대한 소개입니다.
- 데이터셋의 출처
- Shutterstock에서 제공한 이미지와 캡션
- 약 26,000개의 고품질 이미지로 구성
- 관련 메타데이터 포함
- 데이터셋의 특징
- 다양한 카테고리의 광범위한 개념 포함
- 종단적 평가(longitudinal evaluation) 가능
- 다양한 제로샷 이미지 캡셔닝 모델 성능 비교 목적
- 챌린지의 핵심 접근 방식
- 특정 훈련 데이터 미제공
- 제로샷 이미지 캡셔닝 목표
- 훈련 단계에서 보지 못한 새로운 데이터에 대한 AI 모델 성능 평가
- 데이터셋의 의의
- 광범위한 시각적 개념 포함
- 모델의 일반화 능력 테스트
- 다양한 성능 지표를 통한 객관전 평가 가능
이 데이터셋은 제로샷 이미지 캡셔닝 연구의 새로운 기준을 제시하고 있습니다.
2-2. Evaluation metrics
이 내용은 NICE 챌린지의 평가 지표에 대한 상세한 설명입니다.
- 주요 평가 지표: CIDEr 점수
- CIDEr: Consensus-based Image Description Evaluation의 약자
- 두 문장 간 유사성 점수 계산
- TF-IDF(Term Frequency Inverse Document Frequency) 가중치 활용
- 문장 내 n-gram (단어나 구의 조합) 의 중요성을 추정하는 방식
- CIDEr 점수의 특징
- 문장 내 특정 n-gram의 가중치 조정
- 전체 캡션 집합에서 드물게 등장하는 n-gram에 높은 가중치 부여
- 현재 텍스트 비교에서 가장 인기 있는 메트릭스 중 하나
- 동점자 발생 시 보조 평가 지표 (우선순위 순)
- SPICE
- METEOR
- ROUGE
- Bleu
이 평가 방식은 이미지 캡셔닝 모델의 성능을 다각도로 객관적으로 측정하기 위한 정교한 접근법을 보여줍니다.
2-3. Challenge phases
이 내용은 NICE 챌린지의 진행 단계를 상세히 설명하고 있습니다.
- 검증 단계 (Validation Phase)
- 기간: 2023년 2월부터 4월까지
- 목적: 참가자들의 초기 모델 테스트 및 데이터 이해
- 주요 특징:
- 검증 서버 제공
- 참가자들의 예측 결과 업로드 가능
- 정답 캡션(ground truth) 접근 허용
- 데이터 형식과 전략 수립 지원
- 테스트 단계 (Test Phase)
- 기간: 2023년 4월
- 주요 특징:
- 테스트 서버 오픈
- 참가자당 최대 5회 결과 제출 가능
- CIDEr 점수 기준 최고 성적 리더보드 공개
- 정답 캡션 미제공
- 테스트 점수만 참가자에게 공개
이 챌린지 구조는 참가자들에게 점진적인 모델 개발과 평가 기회를 제공하고 있습니다.
2-4. Challenge results
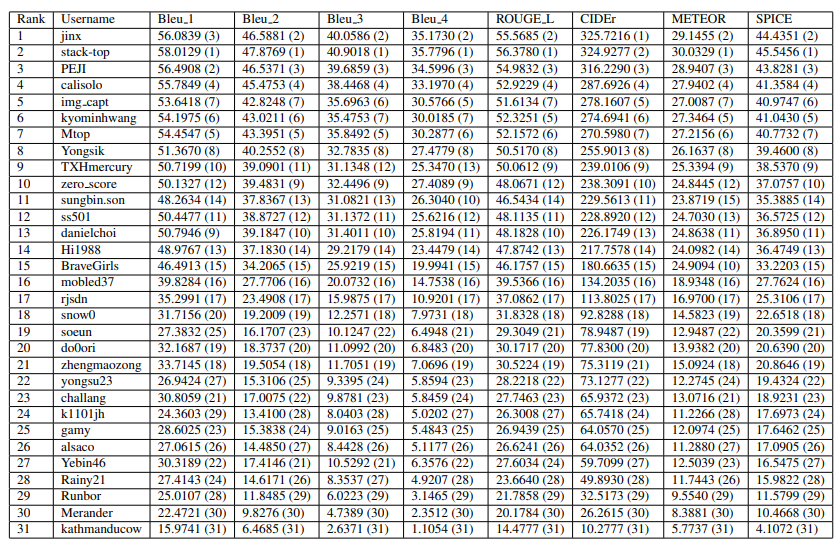
이 내용은 NICE 챌린지의 최종 결과를 요약하고 있습니다.
- 챌린지 참가 현황
- 총 참가 팀: 31개 팀
- 최종 순위 결정 기준: CIDEr 점수
- 상위 팀 성적
- 1위 팀 점수: 325.72
- 2위 팀 점수: 324.93
- 3위 팀 점수: 316.23
- 결과의 특이점
- 1위 팀이 다른 평가 지표에서 반드시 최고점은 아님
- 각 참가팀의 모델이 고유한 강점과 약점 보유
이 결과는 제로샷 이미지 캡셔닝 모델의 복잡성과 다양성을 보여주는 흥미로운 통계를 제시하고 있습니다.
3. Proposed Approaches
3-1. 1st rank : no
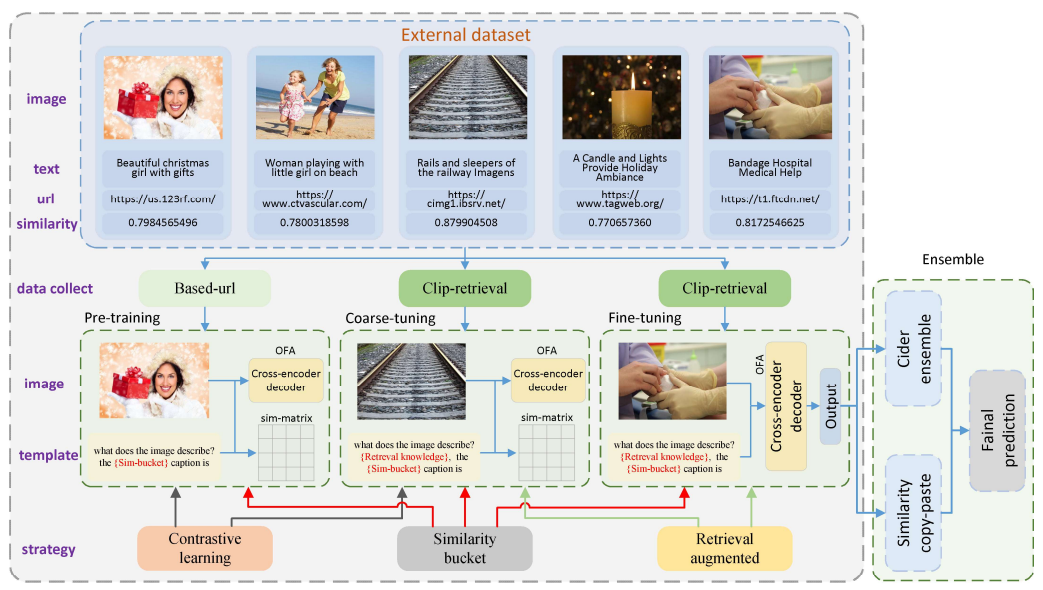
이 내용은 NICE 챌린지 1위 팀의 모델 접근 방식을 설명하고 있습니다.
- 기본 모델 구조
- 기반 모델: OFA (One For All)
- 3단계 아키텍처: (Figure 2 참조)
- Pre-training
- Coarse-tuning
- Fine-tuning
- Pre-training 단계
- 목적: 광범위한 시각적 개념 정렬
- 대조 학습(Contrastive learning) 활용
- 이미지 캡셔닝 사전 학습 목표
- LAION-5B 데이터셋에서 1M 이미지-텍스트 쌍 수집
- Coarse-tuning 단계
- 경쟁 도메인과 유사한 소규모 외부 데이터셋 활용
- 다양한 새로운 개념 학습
- LAION-5B에서 120k 샘플 선택
- Fine-tuning 단계
- 데이터셋 압축
- 검증 데이터셋에 추가
- LAION-5B에서 12k 샘플 선택
- 핵심 전략
- 대조 학습: 단일 모달 표현 개선
- 유사성 버킷 전략: 비전-언어 모델에 다양한 유사성 프롬프트 제공
- 검색 증강 전략: 각 이미지-텍스트 쌍에 대한 미니 지식 베이스 제공
이 접근 방식은 다양한 학습 전략을 통해 제로샷 이미지 캡셔닝 모델의 성능을 극대화하고 있습니다.
3-2. 2nd rank : Retriever
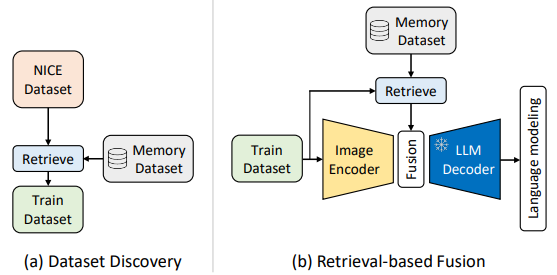
이 내용은 NICE 챌린지 2위 팀의 RETRIEVER 프레임워크 접근 방식을 설명하고 있습니다.
- 접근 배경
- NICE 데이터셋의 도전 과제:
- 새로운 개념 (카메라 앵글 설명)
- 고유 명사 (장소명)
- 제로샷 환경에서 예측 어려움
- NICE 데이터셋의 도전 과제:
- RETRIEVER 프레임워크의 핵심 전략
- 외부 지식을 효율적으로 활용
- 2단계 모델 개선 접근
- 데이터셋 발견 단계 (Dataset Discovery)
- 기본 모델: BLIP-2
- 검색 모듈 활용:
- k-최근접 이웃(kNN) 검색
- 쿼리 이미지와 관련된 외부 이미지-텍스트 쌍 검색
- 중복 제거 후 BLIP-2 미세조정
- 검색 기반 융합 단계 (Retrieval-based Fusion)
- 검색된 이미지-텍스트 쌍의 캡션 임베딩 활용
- 컨텍스트 정보 추가
- 쿼리 특징과 융합
- Q-Former와 LLM 디코더를 통한 캡션 생성
- 성과
- NICE 테스트 분할에서 CIDEr 324.9 달성
- 제로샷 환경에서 모델 성능 향상
이 접근 방식은 외부 지식과 검색 기반 전략을 통해 이미지 캡셔닝 모델의 일반화 능력을 개선하고 있습니다.
3-3. 3rd rank : Kakaobrain-MMU
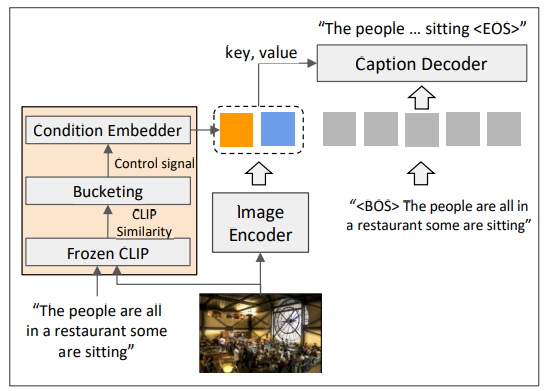
이 내용은 NICE 챌린지 3위 팀인 Kakaobrain-MMU의 접근 방식을 상세히 설명하고 있습니다.
- 접근 방법의 주요 구성 요소
- NoC (Noise-aware Captioning) 프레임워크
- 3단계 훈련 파이프라인
- 합의 기반 모델 앙상블
- NoC 프레임워크
- 웹 크롤링 이미지-텍스트 쌍의 노이즈 처리
- CLIP 유사성을 통한 이미지-텍스트 정렬 수준 모델링
- 추론 단계에서 원하는 정렬 수준의 제어 신호 활용
- 3단계 훈련 파이프라인
- 1단계: 대규모 데이터셋 사전 훈련
- CC15M, COYO-700M, LAION-45M, LAION-120M 등 활용
- 2단계: 검색된 데이터로 미세조정
- NICE와 가장 관련성 높은 이미지-텍스트 쌍 검색
- 3단계: NICE 검증 세트로 최종 미세조정
- 캡션 스타일 정렬
- 1단계: 대규모 데이터셋 사전 훈련
- 합의 기반 앙상블 전략
- N개 캡셔닝 모델로부터 캡션 생성
- 각 캡션의 합의 점수 계산
- CIDEr 점수 기반 캡션 간 유사성 측정
- 최고 합의 점수를 가진 캡션 선택
이 접근 방식은 노이즈 처리, 다단계 훈련, 그리고 정교한 앙상블 전략을 통해 이미지 캡셔닝 모델의 성능을 크게 향상시키고 있습니다.
3-4. 4th rank : Otsuka AI
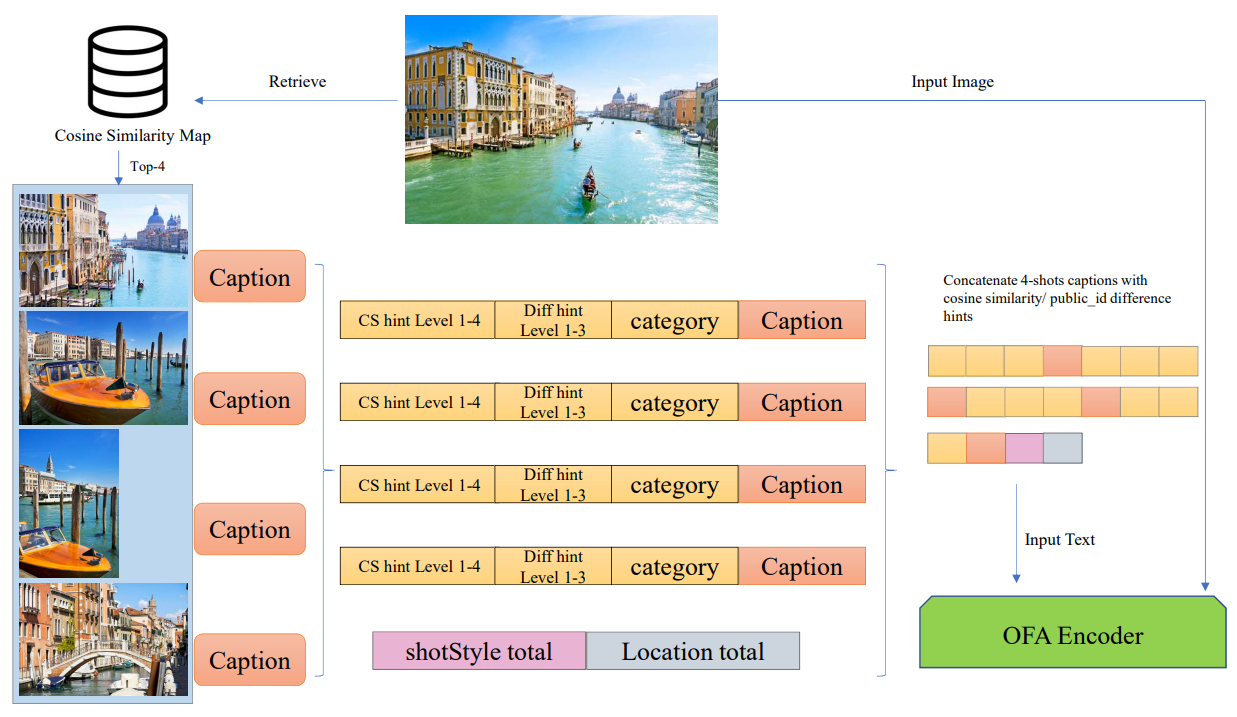
이 내용은 NICE 챌린지 4위 팀의 Otsuka AI 접근 방식을 상세히 설명하고 있습니다.
- 연구 배경 및 도전 과제
- NICE 데이터셋의 난제:
- 지리적 위치(독일, 이탈리아 등) 같은 고유명사 추론
- 이미지만으로 특정 지식 유추의 어려움
- 예: 하이랜드 소의 서식지 추론
- NICE 데이터셋의 난제:
- 접근 방법: "Levels" 방법론
- 기반 모델: OFA(One For All)
- 대화 생성 관점에서 접근
- 페르소나 대화 스타일 모방
- 소프트 프롬프트 활용 전략
- 캡션 힌트의 강도를 분류
- OFA 인코더의 출력층 값 활용
- 입력 이미지와 가장 유사한 4개 이미지 캡션 검색
- 힌트 수준 지정 방법
- 코사인 유사도 기반 4단계 소프트 프롬프트
- 공개 ID 차이 기반 3단계 분류
- 다양한 시각적 프롬프트 기법 활용
- 핵심 기술
- 퓨샷(Few-shot) 프롬프트 기법
- 소프트 프롬프트를 통한 모델 판단 지원
- 언어적 스타일 복제
이 접근 방식은 제한된 컨텍스트에서 이미지 캡셔닝의 정확성을 높이기 위한 혁신적인 전략을 보여줍니다.
3-5. 5th rank : CLAS
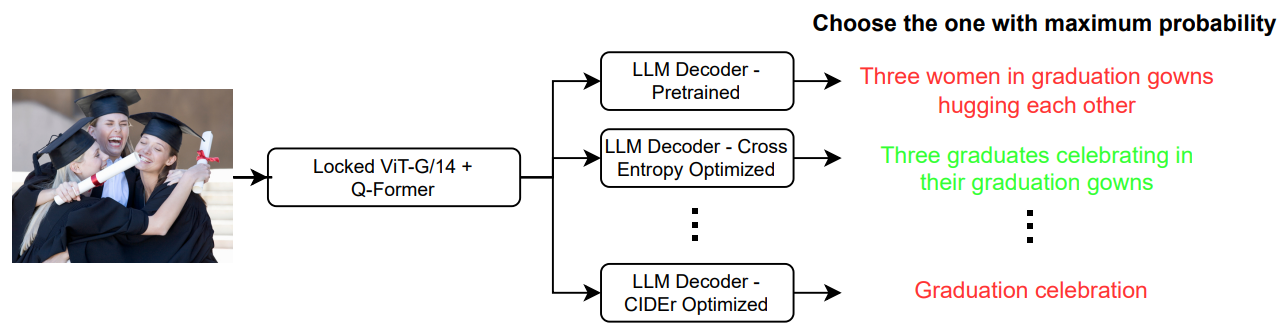
이 내용은 NICE 챌린지 5위 팀의 CLAS 접근 방식을 상세히 설명하고 있습니다.
- 기본 모델 구조
- 기반 모델: BLIP-2
- 구성 요소:
- 이미지 인코더: ViT-G/14
- 언어 모델: OPT-2.7b
- Querying Transformer (Q-Former)
- Q-Former 사전 훈련 전략
- 두 단계 사전 훈련:
- 표현 학습 단계
- 생성적 학습 단계
- 입력 이미지 해상도와 무관한 특징 추출
- 두 단계 사전 훈련:
- 모델 미세조정 방법
- 검증 데이터셋 활용
- "a picture of" 프롬프트 사용
- 200 에포크 동안 훈련
- FP16 혼합 정밀도 훈련
- Low-Rank Adaptation (LoRA) 기법 적용
- 최적화 전략
- 교차 엔트로피 손실 사용
- CIDEr 최적화
- 자기 비평 시퀀스 훈련(self-critical sequence training)
- 앙상블 접근 방식
- 10개 모델 앙상블
- 학습률과 에포크 다양화
- 모델 랭킹 시스템:
- 각 캡션의 신뢰도 점수 기반
- 그리디 샘플링을 통한 확률 계산
- 최고 확률 캡션 선택
이 접근 방식은 다양한 기술적 전략을 통해 제로샷 이미지 캡셔닝 성능을 향상시키고 있습니다.
3-6. 6th rank : MKC
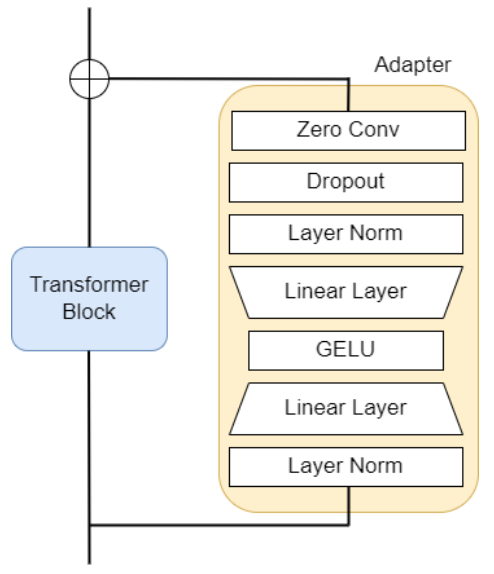
이 내용은 NICE 챌린지 6위 팀의 MKC 접근 방식을 상세히 설명하고 있습니다.
- 기본 모델
- BLIP-2 ViT-g OPT 6.7B 모델 미세조정
- 대규모 비전-언어 사전 훈련 모델
- 모델 개선 전략
- 파라미터 수 감소를 위한 어댑터(Adapter) 추가
- 이미지 인코더에 어댑터 연결
- EMA(Exponential Moving Average) 방법 사용
- 미세조정 과정 (2단계)
- 1단계: CC3M 데이터셋 미세조정
- 2단계: NICE 검증 데이터셋과 CC3M 혼합 데이터 사용
- 기술적 혁신
- Zero convolution 어댑터 구조
- 가중치를 점진적으로 최적화
- 레이어 정규화 최적화
- Q-former 최적화
- 일관성 손실 (Consistency Loss) 적용
- 교사 모델과 학생 모델 간 일관성 유지
- KL 발산 기반 손실 함수 사용
- 성과
- 테스트 케이스에서 274.69 CIDEr 점수 달성
- 경량화된 도메인 강건 미세조정 방법론 입증
이 설명은 대규모 비전-언어 모델의 성능을 효율적으로 개선하는 혁신적인 방법을 보여줍니다.
3-7. 7th rank : Mtop
이 내용은 NICE 챌린지 7위 팀 Mtop의 접근 방식을 상세히 설명하고 있습니다.
- 접근 전략의 핵심
- 데이터 증강(Data Augmentation)
- BEiT3 모델 미세조정
- 제한된 컴퓨팅 자원 활용
- 데이터 처리
- 다양한 캡션 스타일 학습
- 외부 데이터셋 사용 최소화
- BLIP2를 활용한 이미지-텍스트 쌍 유사성 분석
- 사전 훈련 모델
- BEiT3: CC12M, CC3M, SBU, COCO, VG 데이터셋 기반
- NICE 데이터셋과의 캡션 스타일 차이 인식
- 주요 기술적 혁신
- 대규모 언어 모델을 통한 캡션 생성 가이드
- 파괴적 망각(Catastrophic Forgetting) 완화 방법 도입
- 타겟 캡션 스타일 고려
- 성과
- 챌린지 7위 달성
- CIDEr 점수 270점
- 제로샷 학습 성능 개선
이 접근 방식은 제한된 자원으로 이미지 캡셔닝 모델의 성능을 혁신적으로 개선한 사례를 보여줍니다.
4. Conclusion
이 내용은 NICE 챌린지 2023의 결론을 요약하고 있습니다.
- NICE 챌린지의 주요 성과
- 제로샷 이미지 캡셔닝 평가를 위한 새로운 데이터셋 제안
- AI 모델을 새로운 평가 데이터셋에 적응시키기 위한 다양한 접근 시도
- 연구의 핵심 인사이트
- 충분한 타겟 도메인 훈련 데이터 없이 사전 학습된 모델 적응 방법 탐구
- 다양한 도메인과 스타일의 비전-언어 문제 해결 접근
- 연구의 미래 방향
- 비전-언어 모델의 더욱 도전적인 과제 연구 지속
이 결론은 NICE 챌린지가 비전-언어 AI 연구의 새로운 지평을 열었음을 강조하고 있습니다.
Reference
논문 출저: NICE: CVPR 2023 Challenge on Zero-shot Image Captioning Sequence to Sequence Learning with Neural Networks



