Abstract
이 논문의 주요 내용을 요약하면 다음과 같습니다:
- 연구 목적:
- 대규모 데이터셋에서 단어의 연속적인 벡터 표현을 계산하기 위한 두 가지 새로운 모델 아키텍처 제안
- 평가 방법:
- 단어 유사성 작업을 통해 표현의 품질 측정
- 기존의 최고 성능 신경망 기반 기법들과 결과 비교
- 주요 성과:
- 정확도의 큰 향상 달성
- 계산 비용 대폭 감소
- 16억 단어 데이터셋에서 고품질 단어 벡터를 하루 미만으로 학습 가능
- 성능 검증:
- 구문 및 의미적 단어 유사성 측정을 위한 테스트 세트에서 최첨단 성능 달성
- 의의:
- 대규모 데이터에서 효율적이고 고품질의 단어 표현 학습 방법 제시
- 계산 효율성과 성능 향상을 동시에 달성
이 연구는 자연어 처리 분야에서 단어 표현 학습의 효율성과 품질을 크게 개선하는 새로운 방법을 제시하고 있으며, 특히 대규모 데이터셋에서의 빠른 학습과 우수한 성능을 강조하고 있습니다.
1. Introduction
이 내용은 자연어 처리(NLP)에서 단어 표현 방식의 발전과 그 필요성에 대해 설명하고 있습니다.
- 전통적인 NLP 접근 방식:
- 단어를 원자 단위로 취급
- 어휘집의 인덱스로 단어 표현
- 장점: 단순성, 견고성
- 대규모 데이터에서 훈련된 단순 모델이 소규모 데이터의 복잡한 시스템보다 우수한 성능
- 기존 방식의 한계:
- N-gram 모델과 같은 단순 기법들이 많은 작업에서 한계에 도달
- 특정 도메인(예: 음성 인식, 기계 번역)에서 고품질 데이터의 양이 제한적
- 단순한 확장으로는 더 이상의 중요한 발전을 이루기 어려움
- 새로운 접근의 필요성:
- 더 복잡한 모델을 더 큰 데이터셋에서 훈련시키는 것이 가능해짐
- 복잡한 모델이 일반적으로 단순 모델보다 우수한 성능을 보임
- 분산 표현(Distributed Representations)의 중요성:
- 단어의 분산 표현 사용이 가장 성공적인 개념으로 부상
- 신경망 기반 언어 모델이 N-gram 모델보다 뛰어난 성능 발휘
- 발전 방향:
- 단어 간 유사성을 포착할 수 있는 더 발전된 기법에 초점을 맞출 필요성 강조
- 기계 학습 기술의 진보로 대규모 데이터셋에서 복잡한 모델 훈련 가능
이 설명은 NLP 분야에서 단어 표현 방식의 진화 필요성과 분산 표현의 중요성을 강조하며, 연구의 배경과 동기를 제시하고 있습니다.
1-1. Goals of the Paper
- 연구 목표:
- 대규모 데이터셋(수십억 단어)과 대규모 어휘(수백만 단어)에서 고품질 단어 벡터를 학습하는 기술 소개
- 기존 연구의 한계(수억 단어, 50-100 차원의 벡터) 극복
- 벡터 표현의 품질 측정:
- 최근 제안된 기술을 사용하여 벡터 표현의 품질 평가
- 유사한 단어들이 서로 가까울 뿐만 아니라, 다중 유사도 차원을 가질 것으로 예상
- 단어 표현의 특성:
- 단순한 구문적 규칙성을 넘어선 단어 표현의 유사성 발견
- 굴절어에서 관찰된 다중 어미 유사성
- 벡터 연산을 통한 의미적 관계 표현 (예: King - Man + Woman ≈ Queen)
- 새로운 모델 아키텍처:
- 단어 간의 선형적 규칙성을 보존하는 새로운 모델 아키텍처 개발
- 벡터 연산의 정확도 최대화 목표
- 평가 방법:
- 구문적, 의미적 규칙성을 측정하기 위한 새로운 종합 테스트 세트 설계
- 높은 정확도로 많은 규칙성을 학습할 수 있음을 보여줌
- 연구 범위:
- 단어 벡터의 차원과 훈련 데이터의 양에 따른 훈련 시간과 정확도의 관계 논의
1-2. PreviousWork
이 내용은 단어의 연속 벡터 표현에 대한 역사적 배경과 이전 연구들을 설명하고 있습니다.
- 단어의 연속 벡터 표현의 역사:
- 오랜 역사를 가지고 있음
- 신경망 언어 모델(NNLM)의 발전:
- 인기 있는 모델 아키텍처:
- 선형 투영 층과 비선형 은닉층을 가진 순방향 신경망 사용
- 단어 벡터 표현과 통계적 언어 모델을 동시에 학습
- 인기 있는 모델 아키텍처:
- 다른 NNLM 아키텍처:
- 단일 은닉층을 가진 신경망으로 단어 벡터를 먼저 학습
- 학습된 단어 벡터를 사용하여 NNLM 훈련
- 전체 NNLM을 구성하지 않고도 단어 벡터 학습 가능
- 단어 벡터의 응용:
- 많은 NLP 애플리케이션의 성능 향상 및 단순화에 기여
- 다양한 단어 벡터 학습 방법:
- 여러 모델 아키텍처와 다양한 코퍼스를 사용하여 학습
- 일부 학습된 단어 벡터는 향후 연구 및 비교를 위해 공개됨
- 계산 효율성:
- 대부분의 아키텍처는 특정 모델보다 계산적으로 더 비용이 많이 듦
- 예외: 대각 가중치 행렬을 사용하는 log-bilinear 모델의 특정 버전
- 본 연구의 접근:
- 특정 아키텍처를 직접 확장
- 단어 벡터를 학습하는 첫 번째 단계에 초점을 맞춤
- 간단한 모델을 사용하여 단어 벡터 학습에 집중
이 설명은 단어 벡터 표현 학습의 발전 과정을 보여주며, 본 연구가 기존 방법들의 한계를 극복하고 더 효율적인 학습 방법을 제시합니다.
2. Model Architectures
이 내용은 단어의 연속 표현을 추정하는 다양한 모델들과 본 연구의 접근 방식을 설명하고 있습니다.
- 단어 표현 모델의 다양성:
- 잠재 의미 분석(LSA)
- 잠재 디리클레 할당(LDA)
- 신경망 기반 분산 표현
- 연구 초점:
- 신경망으로 학습된 단어의 분산 표현에 집중
- 이유: LSA보다 단어 간 선형 규칙성 보존에 더 우수한 성능
- LDA의 한계: 대규모 데이터셋에서 계산 비용이 매우 높음
- 모델 평가 기준:
- 계산 복잡도: 모델 학습에 필요한 매개변수 수
- 목표: 정확도 최대화와 계산 복잡도 최소화의 균형
- 모델 훈련 복잡도:
- O =E×T×Q로 표현
- E: 훈련 에폭 수 (일반적으로 3-50)
- T: 훈련 세트의 단어 수 (최대 10억 단어)
- Q: 각 모델 아키텍처에 따라 정의되는 값
- O =E×T×Q로 표현
- 훈련 방법:
- 확률적 경사 하강법(Stochastic Gradient Descent) 사용
- 역전파(Backpropagation) 알고리즘 적용
- 데이터셋 규모:
- 최대 10억 단어의 대규모 데이터셋 사용 가능
이 설명은 신경망 기반 분산 표현의 우수성을 강조하며, 모델의 성능을 평가하는 데 있어 정확도와 계산 효율성의 균형을 중요하게 고려하고 있음을 보여줍니다.
2-1. Feedforward Neural Net Language Model (NNLM)
이 내용은 확률적 순방향 신경망 언어 모델(NNLM)의 구조와 계산 복잡도에 대해 설명하고 있습니다.
- NNLM 구조:
- 입력층, 투영층, 은닉층, 출력층으로 구성
- 입력층: N개의 이전 단어를 1-of-V 코딩으로 인코딩 (V는 어휘 크기)
- 투영층: N * D 차원, 공유 투영 행렬 사용
- 은닉층: 일반적으로 500-1000 유닛
- 출력층: 어휘 크기 V 차원
- 계산 복잡도:
- 예시당 계산 복잡도: Q=N×D+N×D×H+H×V
- 주요 비용: H * V 항 (은닉층과 출력층 사이의 계산)
- 계산 효율성 개선 방법:
- 계층적 소프트맥스 사용 [25, 23, 18]
- 훈련 중 정규화를 피하는 모델 사용 [4, 9]
- 이진 트리 표현으로 출력 유닛 수를 log2(V)로 감소
- 허프만 트리 사용:
- 어휘를 허프만 이진 트리로 표현
- 빈도가 높은 단어에 짧은 이진 코드 할당
- 출력 유닛 평가 수를 약 log2(Unigram perplexity(V))로 감소
- 100만 단어 어휘의 경우 약 2배 속도 향상
- 모델의 주요 계산 병목:
- N * D * H 항 (투영층과 은닉층 사이의 계산)
- 향후 제안:
- 은닉층이 없는 새로운 아키텍처 제안 예고
- 소프트맥스 정규화의 효율성에 크게 의존하는 모델
이 설명은 NNLM의 구조와 계산 복잡도를 상세히 분석하고 있으며, 특히 계산 효율성을 높이기 위한 다양한 기법들(계층적 소프트맥스, 허프만 트리 등)을 소개하고 있습니다.
2-2. Recurrent Neural Net Language Model (RNNLM)
이 내용은 순환 신경망 기반 언어 모델(RNN-LM)에 대해 설명하고 있습니다.
- RNN-LM의 목적:
- 순방향 NNLM의 한계 극복
- 문맥 길이(모델의 차수 N) 지정 필요성 제거
- 얕은 신경망보다 더 복잡한 패턴을 효율적으로 표현 가능 [15, 2]
- RNN 모델 구조:
- 입력층, 은닉층, 출력층으로 구성
- 투영층 없음
- 특징: 은닉층을 자신에게 연결하는 순환 행렬 사용 (시간 지연 연결)
- RNN의 장점:
- 단기 메모리 형성 가능
- 과거 정보를 은닉층 상태로 표현
- 현재 입력과 이전 시간 단계의 은닉층 상태를 기반으로 업데이트
- 계산 복잡도:
- 예시당 복잡도: Q=H×H+H×V
- H: 은닉층의 크기 (단어 표현 D와 동일한 차원)
- V: 어휘 크기
- 계산 효율성 개선:
- 계층적 소프트맥스 사용으로 H * V를 H * log2(V)로 감소 가능
- 주요 계산 비용: H * H 항 (은닉층 내부 연산)
이 설명은 RNN-LM의 구조와 장점을 다루며, RNN이 이전 모델의 한계를 극복하고 시간 정보를 처리하는 방법을 설명합니다.
2-3. Parallel Training of Neural Networks
이 내용은 대규모 데이터셋에 대한 분산 학습 프레임워크의 구현에 대한 설명입니
- 분산 프레임워크:
- DistBelief [6]라는 대규모 분산 프레임워크 사용
- 순방향 NNLM과 본 논문에서 제안하는 새로운 모델들을 이 프레임워크 위에 구현
- 병렬 처리 방식:
- 동일한 모델의 여러 복제본을 병렬로 실행
- 각 복제본은 중앙 서버를 통해 그래디언트 업데이트를 동기화
- 중앙 서버가 모든 매개변수를 관리
- 훈련 알고리즘:
- 미니배치 비동기 경사 하강법 사용
- Adagrad라는 적응형 학습률 절차 적용
- 규모:
- 일반적으로 100개 이상의 모델 복제본 사용
- 각 복제본은 데이터 센터의 다른 기계에서 여러 CPU 코어 활용
- 분산 학습의 이점:
- 대규모 데이터셋에 대한 효율적인 학습 가능
- 병렬 처리를 통한 훈련 시간 단축
- 중앙 서버를 통한 효과적인 매개변수 관리
이 설명은 대규모 데이터셋에서 효율적으로 모델을 훈련시키기 위해 사용한 고급 분산 컴퓨팅 기술을 소개하고 있습니다.
3. New Log-linear Models
이 내용은 새로운 단어 분산 표현 학습 모델 아키텍처를 소개하고 있습니다.
- 새로운 모델 제안의 목적:
- 계산 복잡도를 최소화하는 단어 분산 표현 학습 모델 개발
- 기존 모델의 한계:
- 비선형 은닉층이 주요 계산 복잡도의 원인
- 신경망의 강점이지만 효율성의 제약 요인
- 새로운 접근 방식:
- 더 단순한 모델 탐색
- 데이터 표현의 정밀도는 다소 낮을 수 있으나, 대규모 데이터에 대해 효율적으로 학습 가능한 모델 추구
- 이전 연구와의 연관성:
- 신경망 언어 모델을 두 단계로 나누어 훈련
- a) 단순 모델을 사용해 연속적 단어 벡터 학습
- b) 학습된 분산 표현 위에 N-gram NNLM 훈련
- 신경망 언어 모델을 두 단계로 나누어 훈련
- 접근 방식의 특징:
- 이전 연구에서 제안된 방법을 가장 단순한 접근법으로 간주
- 유사한 모델들이 이전에도 제안됨
- 연구의 의의:
- 단어 벡터 학습에 초점을 맞춘 후속 연구들의 기반 제공
- 계산 효율성과 대규모 데이터 처리 능력 향상 추구
이 설명은 기존 신경망 모델의 복잡성을 줄이면서도 대규모 데이터에 효율적으로 적용할 수 있는 새로운 모델 아키텍처를 개발하고자 하는 목표를 보여줍니다.
3-1. Continuous Bag-of-Words Model
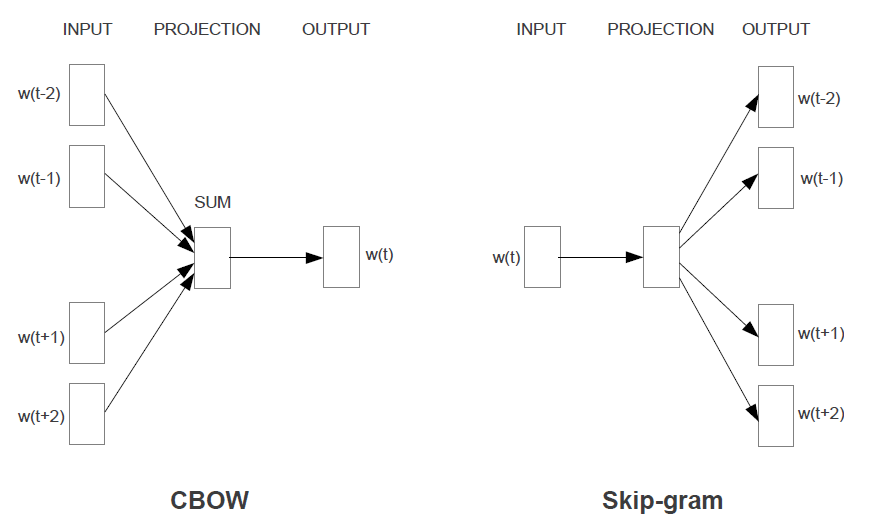
이 내용은 논문에서 제안하는 첫 번째 모델 아키텍처에 대해 설명하고 있습니다.
- 모델 명칭: CBOW (Continuous Bag-of-Words)
- 기존 NNLM과의 차이점:
- 비선형 은닉층 제거
- 모든 단어에 대해 투영 계층 공유 (투영 행렬만 공유하는 것이 아님)
- 주요 특징:
- 모든 단어가 같은 위치로 투영됨 (벡터들이 평균화됨)
- 단어의 순서가 투영에 영향을 미치지 않음 (bag-of-words 모델의 특성)
- 컨텍스트 사용:
- 과거 단어뿐만 아니라 미래 단어도 사용
- 최적의 성능을 위해 4개의 미래 단어와 4개의 과거 단어를 입력으로 사용
- 학습 목표:
- 현재(중간) 단어를 올바르게 분류하는 log-linear 분류기 구축
- 학습 복잡도: Q = N × D + D × log2(V) (N: 단어 벡터의 차원, D: 은닉 레이어의 차원, V: 어휘 크기)
- CBOW의 특징:
- 표준 bag-of-words 모델과 달리 컨텍스트의 연속적 분산 표현 사용
- 입력과 투영 계층 사이의 가중치 행렬이 모든 단어 위치에 대해 공유됨 (NNLM과 유사)
- 모델 구조:
- Figure 1에서 시각적으로 제시됨
이 설명은 기존 NNLM의 구조를 단순화하면서도 컨텍스트의 분산 표현을 유지하여 효율적인 단어 벡터 학습을 가능하게 합니다.
3-2. Training on Multiple GPUs
이 내용은 논문에서 제안하는 두 번째 모델 아키텍처에 대해 설명하고 있습니다.
- 모델 특성:
- CBOW와 유사하지만 예측 방식이 다름
- 현재 단어를 기반으로 컨텍스트를 예측하는 대신, 같은 문장 내의 다른 단어를 기반으로 단어를 분류
- 작동 방식:
- 각 현재 단어를 연속 투영 계층을 가진 log-linear 분류기의 입력으로 사용
- 현재 단어 전후의 특정 범위 내 단어들을 예측
- 범위 설정:
- 범위를 늘리면 결과 단어 벡터의 품질이 향상되지만 계산 복잡도도 증가
- 거리가 먼 단어들은 현재 단어와의 관련성이 낮아 학습 예제에서 덜 샘플링됨
- 학습 복잡도: Q = C × (D + D × log2(V)) C: 최대 단어 거리 D: 은닉 레이어의 차원 V: 어휘 크기
- 트레이닝 과정:
- 각 훈련 단어에 대해 1에서 C 사이의 랜덤 숫자 R을 선택
- 현재 단어의 과거와 미래에서 각각 R개의 단어를 정답 레이블로 사용
- 총 R×2 단어 분류 수행 (현재 단어가 입력, R+R 단어가 각각 출력)
- 실험 설정:
- C = 10 사용
이 설명은 Skip-gram 모델로 알려져 있으며, CBOW와는 반대로 주변 단어들을 예측하는 방식으로 학습합니다.
4. Results
이 내용은 단어 벡터의 질을 평가하는 새로운 방법과 그 결과에 대해 설명하고 있습니다.
- 기존 평가 방법의 한계:
- 유사한 단어 목록을 통한 직관적 이해
- 더 복잡한 유사성 작업에서의 평가 필요성
- 새로운 평가 방법:
- 단어 간의 다양한 유사성 유형 고려
- 예: "big"과 "bigger"의 관계 vs "small"과 "smaller"의 관계
- 단어 관계 질문 형식:
- 예: "What is the word that is similar to small in the same sense as biggest is similar to big?"
- 벡터 연산을 통한 답변 도출:
- 간단한 대수 연산으로 질문에 대한 답 찾기
- 예: vector("biggest") - vector("big") + vector("small") ≈ vector("smallest")
- 코사인 거리로 가장 가까운 단어 검색
- 고차원 단어 벡터의 성능:
- 대량의 데이터로 훈련 시 미묘한 의미 관계 포착 가능
- 예: 도시와 국가의 관계 (Paris:France :: Berlin:Germany)
- 응용 가능성:
- 기존 NLP 애플리케이션 개선:
- 기계 번역
- 정보 검색
- 질문 답변 시스템
- 새로운 애플리케이션 개발 가능성
- 기존 NLP 애플리케이션 개선:
이 설명은 단어 벡터가 단순한 유사성을 넘어 복잡한 의미적, 구문적 관계를 포착할 수 있음을 보여줍니다.
4-1. Task Description
이 내용은 단어 벡터의 품질을 측정하기 위한 종합적인 테스트 세트와 평가 방법에 대해 설명하고 있습니다.
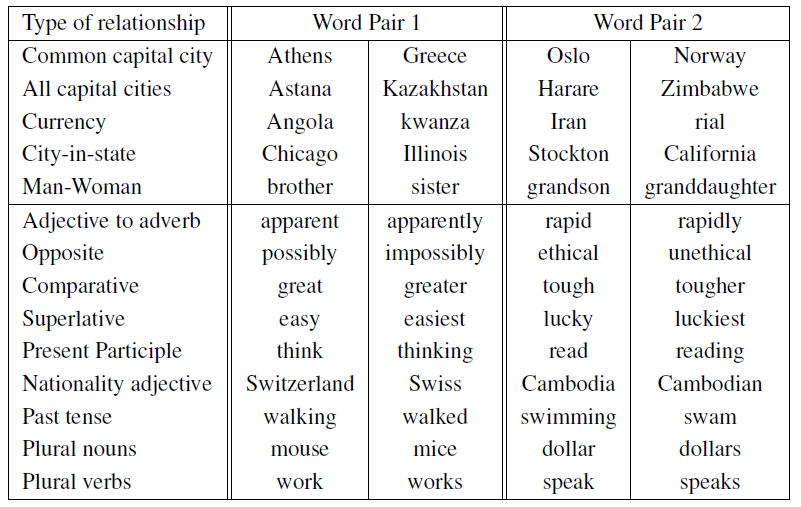
- 테스트 세트 구성:
- 5가지 유형의 의미적(semantic) 질문
- 9가지 유형의 구문적(syntactic) 질문
- 총 19,544개의 질문 (의미적: 8,869개, 구문적: 10,675개)
- 테스트 세트 생성 방법:
- 수동으로 유사한 단어 쌍 목록 작성
- 두 단어 쌍을 연결하여 대규모 질문 목록 형성
- 예: 68개의 미국 대도시와 해당 주를 연결하여 약 2,500개의 질문 생성
- 테스트 세트 제한 사항:
- 단일 토큰 단어만 포함 (예: "New York"과 같은 다중 단어 엔티티 제외)
- 평가 방법:
- 전체 정확도 및 각 질문 유형별 정확도 평가
- 벡터 연산 결과가 정확히 일치하는 경우만 정답으로 간주
- 동의어는 오답으로 처리
- 평가 기준의 특징:
- 100% 정확도 달성은 현실적으로 불가능
- 현재 모델들은 단어의 형태학적 정보를 입력으로 받지 않음
- 평가 방법의 의의:
- 이 정확도 지표가 특정 응용 프로그램에서의 단어 벡터 유용성과 양의 상관관계를 가질 것으로 예상
- 단어의 구조에 대한 정보를 포함시킴으로써 추가적인 발전 가능성 존재 (특히 구문적 질문에서)
이 설명은 단어 벡터가 단순한 유사성을 넘어 복잡한 의미적, 구문적 관계를 얼마나 잘 포착하는지 측정할 수 있게 해줍니다.
4-2. Maximization of Accuracy
이 내용은 단어 벡터 학습을 위한 실험 설정과 결과에 대해 설명하고 있습니다.
- 훈련 데이터:
- Google News 코퍼스 사용
- 약 60억 토큰 포함
- 어휘 크기를 가장 빈번한 100만 단어로 제한
- 최적화 문제:
- 더 많은 데이터와 더 높은 차원의 단어 벡터가 정확도를 향상시킬 것으로 예상
- 시간 제약 하에서의 최적화 문제로 인식
- 초기 평가:
- 훈련 데이터의 부분집합 사용
- 어휘를 가장 빈번한 3만 단어로 제한
- CBOW 아키텍처 사용
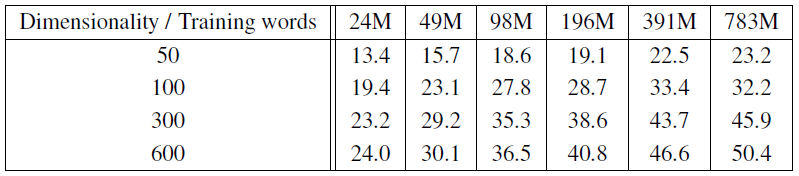
- 다양한 단어 벡터 차원과 증가하는 훈련 데이터량에 따른 결과를 Table 2에 제시
- 관찰 결과:
- 특정 시점 이후 차원 증가나 훈련 데이터 증가의 효과가 감소
- 벡터 차원과 훈련 데이터량을 함께 증가시켜야 함
- 현재 많은 연구에서 큰 데이터셋으로 훈련하지만 벡터 크기가 불충분한 경향이 있음을 지적
- 훈련 방법:
- 3번의 훈련 에폭 사용
- 확률적 경사 하강법(SGD)과 역전파 사용
- 초기 학습률 0.025에서 시작하여 마지막 에폭에서 0에 근접하도록 선형적으로 감소
이 설명은 대규모 데이터셋에서 효과적인 단어 벡터 학습을 위한 실용적인 접근 방식을 보여줍니다.
4-3. Comparison of Model Architectures
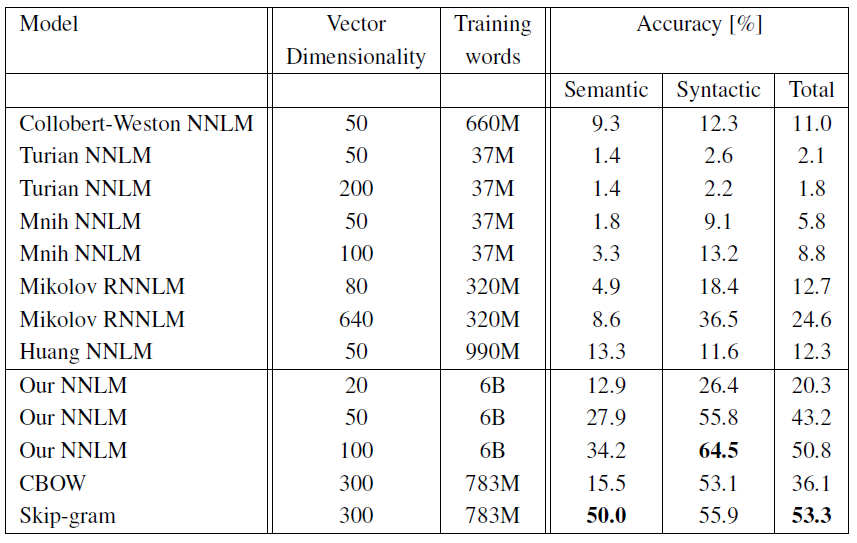
이 내용은 논문에서 제안한 모델들의 성능 평가와 비교 실험에 대해 설명하고 있습니다.
- 실험 설정:
- 동일한 훈련 데이터와 640차원의 단어 벡터를 사용하여 다양한 모델 아키텍처 비교
- Semantic-Syntactic Word Relationship 테스트 세트와 구문적 유사성에 초점을 맞춘 추가 테스트 세트 사용
- 훈련 데이터: LDC 코퍼스 (320M 단어, 82K 어휘)
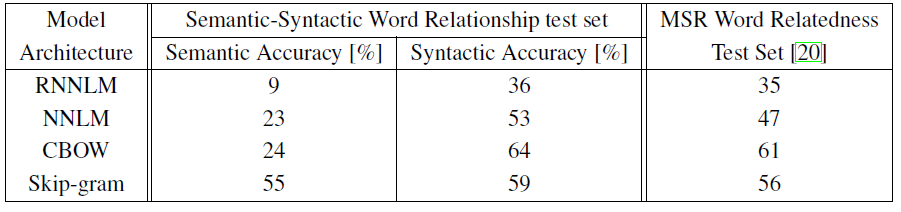
- 모델 비교:
- 순환 신경망 언어 모델(RNNLM): 구문 질문에서 좋은 성능 (Table 3 참조)
- 순방향 신경망 언어 모델(NNLM): RNNLM보다 전반적으로 우수한 성능
- CBOW (Continuous Bag-of-Words): 구문 작업에서 NNLM보다 우수, 의미 작업에서 유사한 성능
- Skip-gram: 구문 작업에서 CBOW보다 약간 낮지만 NNLM보다 우수, 의미 작업에서 모든 모델 중 가장 우수한 성능 (Table 4 참조)
- 훈련 효율성:
- CBOW 모델: Google News 데이터 부분집합으로 약 1일 훈련
- Skip-gram 모델: 약 3일 훈련 소요
- 단일 CPU 사용
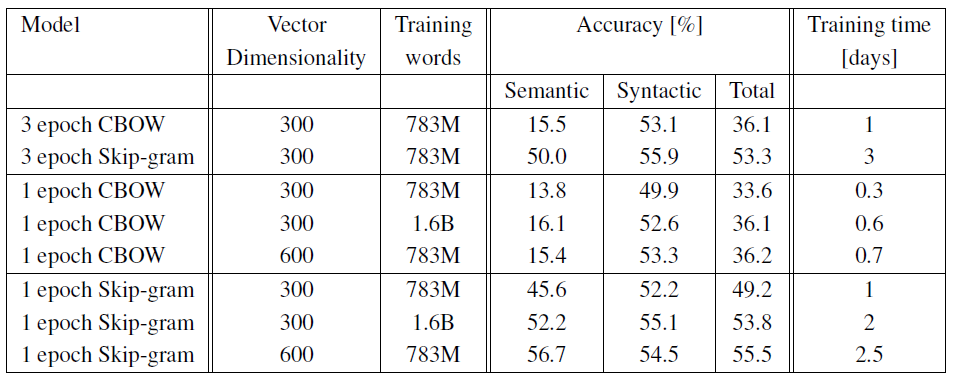
- 훈련 전략:
- 단일 에폭(epoch) 훈련이 효과적임을 발견
- 학습률을 선형적으로 감소시켜 훈련 종료 시 0에 근접하도록 함
- 두 배의 데이터로 1회 에폭 훈련이 동일 데이터로 3회 에폭 훈련보다 비슷하거나 더 나은 결과 제공 (Table 5 참조)
- 공개된 단어 벡터와의 비교:
- 제안된 모델들이 공개된 단어 벡터들과 비교하여 우수한 성능 보임
이 설명은 제안된 CBOW와 Skip-gram 모델이 기존 모델들보다 효율적이면서도 더 나은 성능을 제공함을 보여주고 있습니다.
4-4. Large Scale Parallel Training of Models
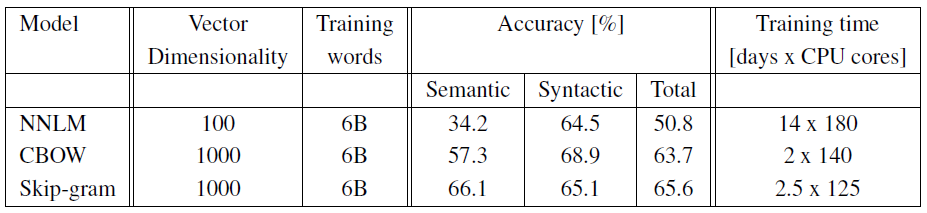
이 내용은 분산 프레임워크인 DistBelief를 사용한 대규모 실험 결과에 대해 설명하고 있습니다.
- 실험 환경:
- 사용된 데이터셋: Google News 6B 데이터셋
- 분산 프레임워크: DistBelief
- 훈련 방법:
- 미니배치 비동기 경사 하강법 사용
- Adagrad 적응적 학습률 절차 적용
- 분산 처리 규모:
- 50에서 100개의 모델 복제본 사용
- CPU 코어 수는 추정치 (데이터 센터 기계가 다른 작업과 공유되어 사용량 변동 가능)
- 모델 비교:
- CBOW 모델과 Skip-gram 모델의 CPU 사용량이 단일 기계 구현에 비해 더 유사해짐
- 이는 분산 프레임워크의 오버헤드로 인한 것으로 설명
- 결과 보고:
- 실험 결과는 Table 6에 요약되어 있음
- 분산 학습의 의의:
- 대규모 데이터셋에 대한 효율적인 모델 훈련 가능
- 단일 기계 구현과 비교하여 훈련 시간 단축 예상
이 설명은 제안된 모델들이 대규모 데이터셋에서도 효과적으로 훈련될 수 있음을 보여주며, 분산 컴퓨팅을 통한 대규모 자연어 처리 모델 훈련의 실현 가능성을 입증하고 있습니다.
4-5. Microsoft Research Sentence Completion Challenge
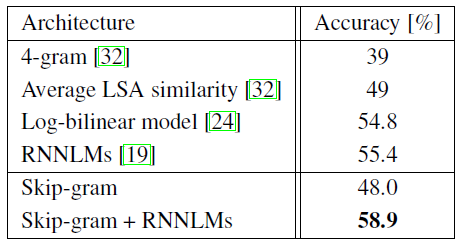
이 내용은 Microsoft Sentence Completion Challenge에 대한 Skip-gram 모델의 성능을 평가하고 있습니다.
- Microsoft Sentence Completion Challenge 소개:
- 1040개의 문장으로 구성
- 각 문장에서 한 단어가 누락되어 있으며, 5개의 선택지 중 가장 적절한 단어를 선택하는 과제
- 언어 모델링과 NLP 기술 발전을 위한 벤치마크로 사용됨
- 기존 기법들의 성능:
- N-gram 모델, LSA 기반 모델, log-bilinear 모델 등이 이미 평가됨
- 순환 신경망(RNN) 조합 모델이 현재 최고 성능인 55.4% 정확도 기록
- Skip-gram 모델의 적용:
- 640차원 모델을 50M 단어 데이터셋으로 훈련
- 테스트 세트의 각 문장에 대해 점수 계산
- 누락된 단어를 입력으로 사용하여 주변 단어들을 예측
- 개별 예측의 합을 최종 문장 점수로 사용
- 가장 높은 점수를 가진 문장 선택
- 결과 (Table 7 요약):
- Skip-gram 모델 자체는 LSA 유사도보다 뛰어난 성능을 보이지 않음
- 그러나 Skip-gram 모델의 점수는 RNNLM과 상호 보완적
- 새로운 최고 성능 달성:
- Skip-gram과 RNNLM의 가중치 조합으로 58.9% 정확도 달성
- 개발 세트: 59.2% 정확도
- 테스트 세트: 58.7% 정확도
- 이는 이전의 최고 성능을 뛰어넘는 새로운 기록
- Skip-gram과 RNNLM의 가중치 조합으로 58.9% 정확도 달성
이 설명은 Skip-gram 모델이 단독으로는 이 특정 과제에서 최고 성능을 내지 못하지만, 다른 모델들과 조합했을 때 성능 향상에 기여할 수 있음을 보여줍니다.
5. Examples of the Learned Relationships
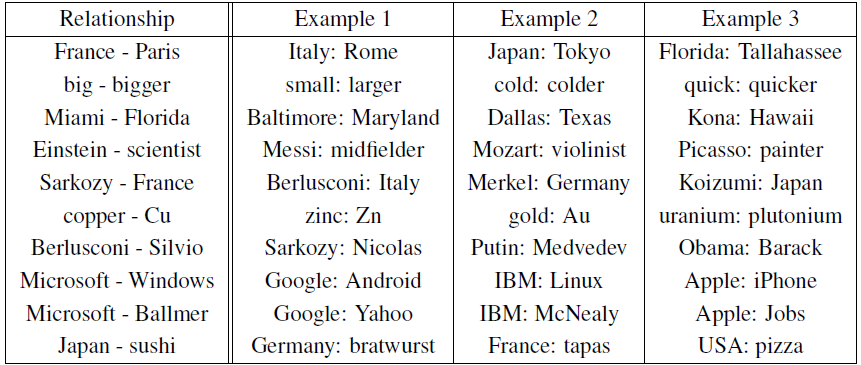
이 내용은 단어 벡터 연산을 통한 의미적 관계 추론과 그 결과에 대해 설명하고 있습니다.
- 단어 관계 추론 방법:
- 두 단어 벡터의 차이를 계산하여 관계를 정의
- 이 관계 벡터를 다른 단어에 더하여 새로운 단어 추론
- 예: Paris - France + Italy = Rome
- 결과 평가:
- Table 8에서 다양한 관계에 대한 예시 제시
- 정확도가 상당히 좋은 편이나 개선의 여지가 있음
- 정확한 일치를 가정한 평가 기준으로는 약 60% 정도의 점수
- 성능 개선 방안:
- 더 큰 데이터셋과 더 높은 차원의 단어 벡터 사용
- 관계 정의에 여러 예시 사용 (10개 예시 사용 시 약 10% 정확도 향상 관찰)
- 다른 응용 가능성:
- 목록에서 이질적인 단어 선택 문제에 적용 가능
- 단어 목록의 평균 벡터를 계산하고 가장 먼 단어 벡터 찾기
- 이는 인간 지능 테스트의 일반적인 문제 유형과 유사
- 향후 전망:
- 이 기술을 사용한 새로운 혁신적 응용 프로그램 개발 가능성
- 아직 많은 발견이 이루어질 여지가 있음을 강조
이 설명은 단어 벡터 모델의 실제적인 응용과 그 잠재력을 보여주고 있습니다. 특히 단순한 벡터 연산을 통해 복잡한 의미적 관계를 포착할 수 있다는 점이 강조되며, 이는 자연어 처리 분야에서 중요한 발전을 시사합니다.
6. Results
이 내용은 논문의 결론 부분으로, 연구의 주요 발견과 향후 전망을 요약하고 있습니다.
- 연구 요약:
- 다양한 모델로 생성된 단어 벡터 표현의 품질을 구문 및 의미 언어 작업에서 평가
- 주요 발견:
- 간단한 모델 구조로도 고품질의 단어 벡터 생성 가능
- 낮은 계산 복잡성으로 더 큰 데이터셋에서 정확한 고차원 단어 벡터 계산 가능
- 대규모 적용 가능성:
- DistBelief 분산 프레임워크를 사용하여 1조 단어 규모의 코퍼스에 대해 CBOW와 Skip-gram 모델 훈련 가능
- 이는 기존 발표된 유사 모델 결과보다 몇 배 더 큰 규모임
- 성능 향상 사례:
- SemEval-2012 Task 2에서 이전 최고 성능 대비 50% 이상의 성능 향상 달성
- 응용 분야:
- 감성 분석, 패러프레이즈 탐지 등 다양한 NLP 작업에 적용 가능
- 지식 베이스의 자동 확장 및 기존 사실 검증에 성공적으로 적용
- 기계 번역 실험에서도 유망한 결과 도출
- 향후 연구 방향:
- Latent Relational Analysis 등 다른 기법과의 비교
- 제안된 종합적인 테스트 세트를 통한 단어 벡터 추정 기술의 지속적 개선
- 고품질 단어 벡터가 향후 NLP 응용의 중요한 구성 요소가 될 것으로 예상
- 의의:
- 단순하면서도 효과적인 모델 아키텍처 제시
- 대규모 데이터에 적용 가능한 효율적인 학습 방법 제안
- 다양한 NLP 작업에서의 성능 향상 가능성 제시
이 설명은 연구의 주요 성과를 요약하고, 제안된 모델의 실용성과 확장성을 강조하며, 자연어 처리 분야에서의 광범위한 응용 가능성을 제시하고 있습니다.
7. Follow-Up Work
이 내용은 논문의 초기 버전 이후의 후속 작업과 발전 사항에 대해 설명하고 있습니다.
- 코드 공개:
- 단일 기계, 다중 스레드 C++ 코드 공개
- CBOW(continuous bag-of-words)와 skip-gram 아키텍처 모두 구현
- 성능 향상:
- 훈련 속도가 초기 논문에서 보고된 것보다 크게 향상됨
- 일반적인 하이퍼파라미터 선택 시 시간당 수십억 단어 처리 가능
- 사전 훈련된 벡터 공개:
- 140만 개 이상의 벡터 공개
- 이 벡터들은 명명된 개체(named entities)를 표현
- 1000억 개 이상의 단어로 훈련됨
- 후속 연구:
- NIPS 2013 학회에서 후속 연구 발표 예정
실용성: 공개된 코드를 통해 다른 연구자들이 이 기술을 쉽게 사용하고 재현할 수 있게 됨
성능: 훈련 속도의 대폭 향상은 더 큰 규모의 데이터셋과 실시간 응용 가능성을 시사
자원 공유: 사전 훈련된 대규모 벡터 세트의 공개는 다른 NLP 작업에 즉시 활용 가능한 자원을 제공
지속적 연구: NIPS 2013 논문 예고는 이 분야의 빠른 발전과 연구의 연속성을 보여줌이 설명은 초기 연구의 영향력과 실용성을 크게 증대시키며, 단어 임베딩 기술의 빠른 발전과 광범위한 적용 가능성을 시사합니다.
Reference
논문 출저: Efficient Estimation of Word Representations in Vector Space



