이 논문은 " Convolutional LSTM Network: A Machine Learning
Approach for Precipitation Nowcasting "이라는 제목의 논문입니다.
작성자는 Xingjian Shi 외 5명이며, 2015년에 발표된 해당 논문은 논문에서는 기상 예측, 특히 강수량 예측(Precipitation Nowcasting)을 위해 새로운 딥러닝 모델인 Convolutional LSTM (ConvLSTM) 네트워크를 제안합니다. ConvLSTM 네트워크는 전통적인 LSTM(Long Short-Term Memory) 네트워크의 장점에 합성곱(Convolutional) 연산을 결합하여, 공간적 및 시간적 패턴을 동시에 학습할 수 있게 합니다.
Abstract
이 논문의 주요 내용을 요약하면 다음과 같습니다:
- 연구 목적: 강수 nowcasting(단기 예측)을 위한 새로운 머신러닝 접근법 제시
- 문제 정의: 강수 nowcasting을 시공간 시퀀스 예측 문제로 정식화
- 입력과 예측 대상 모두 시공간 시퀀스
- 제안 모델: Convolutional LSTM (ConvLSTM)
- 기존 Fully Connected LSTM (FC-LSTM)을 확장
- 입력-상태 및 상태-상태 전이에 합성곱 구조 도입
- 모델 특징: 강수 nowcasting을 위한 end-to-end 학습 가능한 모델
- 실험 결과:
- ConvLSTM이 시공간 상관관계를 더 잘 포착
- FC-LSTM과 기존 최신 기술인 ROVER 알고리즘보다 일관되게 우수한 성능 달성
- 이 연구는 딥러닝 기술을 기상 예측에 적용한 혁신적인 시도로, 시공간 데이터 처리에 특화된 새로운 신경망 구조를 제안했다는 점에서 중요한 의미를 가집니다. ConvLSTM의 도입으로 복잡한 기상 패턴을 더 효과적으로 학습하고 예측할 수 있게 되었습니다.
1. Introduction
강수 nowcasting 문제와 그에 대한 새로운 접근법을 소개
- 강수 nowcasting의 중요성
- 단기(0-6시간) 지역 강수 강도 예측
- 긴급 경보, 공항 기상 지침, 장기 수치 예보 모델과의 통합에 필수적
- 기존 접근법의 한계
- 수치 예보(NWP) 기반 방법: 복잡하고 시간 소요가 큼
- 레이더 에코 외삽 기반 방법: 광학 흐름 기법 사용, 하지만 모델 매개변수 결정이 어려움
- 머신러닝 관점에서의 접근
- 강수 nowcasting을 시공간 시퀀스 예측 문제로 정의
- 고차원 데이터와 대기의 카오스적 특성으로 인한 어려움
- 딥러닝의 발전과 적용
- RNN, LSTM 모델의 발전
- 시퀀스-투-시퀀스 학습 프레임워크 소개
- 기존 FC-LSTM의 한계: 공간적 상관관계를 고려하지 않음
- 제안 모델: Convolutional LSTM (ConvLSTM)
- 입력-상태 및 상태-상태 전이에 합성곱 구조 도입
- 다층 ConvLSTM과 인코딩-예측 구조를 통한 end-to-end 학습 가능 모델 구축
- 평가 및 결과
- 새로운 실제 레이더 에코 데이터셋 생성
- Moving-MNIST 데이터셋과 레이더 에코 데이터셋에서 FC-LSTM과 ROVER 알고리즘 대비 우수한 성능 달성
2. Preliminaries
2-1. Formulation of Precipitation Nowcasting Problem
강수 nowcasting 문제를 보다 형식적으로 정의하고, 이를 시공간 시퀀스 예측 문제로 모델링하는 방법을 설명

- 강수 nowcasting의 목표:
- 이전에 관측된 레이더 에코 시퀀스를 사용하여 미래의 고정 길이 레이더 맵을 예측
- 실제 응용에서는 보통 6-10분 간격으로 레이더 맵을 관측하고, 1-6시간(6-60 프레임) 앞을 예측
- 시공간 시퀀스 예측 문제로의 모델링:
- M×N 그리드로 표현되는 공간 영역 가정
- 각 셀에는 시간에 따라 변하는 P개의 측정값 존재
- 관측값은 X ∈ R^(P×M×N) 텐서로 표현
- 문제의 수학적 정의:
- 이전 J개의 관측값이 주어졌을 때, 가장 가능성 있는 미래 K 길이의 시퀀스 예측
- 조건부 확률 최대화 문제로 표현 ※표 참조
- 강수 nowcasting에의 적용:
- 각 시간의 관측값은 2D 레이더 에코 맵
- 맵을 겹치지 않는 패치로 나누고, 패치 내 픽셀을 측정값으로 간주
- 문제의 특성:
- 단일 단계 시계열 예측과는 다름
- 예측 대상이 공간 및 시간 구조를 모두 포함하는 시퀀스
- 예측 변수의 수가 O(MK×NK×PK)까지 증가할 수 있음
- 실제로는 예측 공간의 구조를 활용하여 차원을 줄이고 문제를 다룰 수 있게 함
이 접근 방식은 강수 nowcasting 문제를 머신러닝, 특히 딥러닝 기법을 적용할 수 있는 형태로 재구성하는 것이 핵심입니다. 시공간 데이터의 특성을 고려하여 문제를 정의함으로써, 복잡한 기상 패턴을 효과적으로 모델링하고 예측할 수 있는 기반을 마련하고 있습니다.
2-2. Long Short-Term Memory for Sequence Modeling
LSTM(Long Short-Term Memory)의 구조와 작동 원리, 그리고 FC-LSTM(Fully Connected LSTM)에 대해 설명
- LSTM의 특징과 장점:
- 일반적인 시퀀스 모델링에 효과적
- 장기 의존성 모델링에 안정적이고 강력함
- 메모리 셀(ct)을 통한 상태 정보 축적
- LSTM의 핵심 구성 요소:
- 메모리 셀(ct): 상태 정보 누적기 역할
- 입력 게이트(it): 새로운 정보의 축적 제어
- 망각 게이트(ft): 과거 셀 상태의 '망각' 제어
- 출력 게이트(ot): 최종 상태(ht)로의 전파 제어
- LSTM의 장점:
- 그래디언트 소실 문제 방지
- 셀 내 그래디언트 포착 (constant error carousels)
- FC-LSTM (Fully Connected LSTM):
- LSTM의 다변량 버전
- 입력, 셀 출력, 상태가 모두 1D 벡터
- FC-LSTM의 수학적 표현:
- 주요 방정식 제시 (입력 게이트, 망각 게이트, 셀 상태, 출력 게이트, 은닉 상태) ※표 참조
- '⊙'는 Hadamard 곱(요소별 곱)을 나타냄
- LSTM의 응용:
- 여러 LSTM을 쌓고 시간적으로 연결하여 복잡한 구조 형성 가능
- 다양한 실제 시퀀스 모델링 문제에 적용

이 설명은 LSTM의 기본 구조와 작동 원리를 소개하고, 이를 FC-LSTM으로 확장하는 과정을 보여줍니다. LSTM의 핵심인 메모리 셀과 게이트 메커니즘이 어떻게 장기 의존성 문제를 해결하는지 설명하고 있으며, 이는 시계열 데이터나 시퀀스 데이터를 다루는 데 매우 효과적임을 강조하고 있습니다. 이러한 LSTM의 특성은 강수 nowcasting과 같은 복잡한 시공간 예측 문제에 적용될 수 있는 기반을 제공합니다.
3. The Model
ConvLSTM 네트워크의 핵심 아이디어와 구조를 소개
- FC-LSTM의 한계:
- 시간적 상관관계 처리에는 강력하지만, 공간 데이터에 대해서는 많은 중복성을 포함
- ConvLSTM의 제안:
- FC-LSTM을 확장한 모델
- 입력-상태 및 상태-상태 전이 모두에 합성곱 구조 도입
- 이를 통해 공간 데이터의 특성을 더 효과적으로 포착
- 네트워크 구조:
- 여러 ConvLSTM 층을 쌓아 구성
- 인코딩-예측 구조 형성
- 적용 범위:
- 강수 nowcasting 문제에 특화되어 있지만,
- 더 일반적인 시공간 시퀀스 예측 문제에도 적용 가능
이 접근 방식의 핵심은 기존 LSTM의 장점을 유지하면서 공간 데이터의 특성을 효과적으로 처리할 수 있는 구조를 설계한 것입니다. ConvLSTM은 시간적 의존성과 공간적 의존성을 동시에 모델링할 수 있어, 레이더 에코 맵과 같은 복잡한 시공간 데이터의 패턴을 학습하고 예측하는 데 매우 적합합니다.
이러한 구조는 다음과 같은 이점을 제공합니다:
- 공간적 지역성(spatial locality) 보존: 합성곱 연산을 통해 인접한 공간 영역의 정보를 효과적으로 처리
- 매개변수 공유: 합성곱 필터의 가중치를 공유함으로써 모델의 복잡도를 줄이고 일반화 능력을 향상
- 다중 스케일 특징 학습: 여러 층을 쌓음으로써 다양한 수준의 시공간 패턴을 포착
- 유연성: 인코딩-예측 구조를 통해 다양한 길이의 입력과 출력 시퀀스를 처리 가능

3-1. Convolutional LSTM
ConvLSTM의 핵심 구조와 작동 원리를 설명
- FC-LSTM의 한계 극복:
- FC-LSTM은 공간 정보를 인코딩하지 않는 완전 연결 구조를 사용
- ConvLSTM은 이를 극복하기 위해 설계됨
- ConvLSTM의 주요 특징:
- 모든 입력, 셀 출력, 은닉 상태, 게이트가 3D 텐서 형태
- 마지막 두 차원이 공간 차원(행과 열)을 나타냄
- 작동 원리:
- 그리드의 특정 셀의 미래 상태를 주변 이웃의 입력과 과거 상태로 결정
- 상태-상태 및 입력-상태 전이에 합성곱 연산자 사용
- ConvLSTM의 핵심 방정식:
- 입력 게이트, 망각 게이트, 셀 상태, 출력 게이트, 은닉 상태를 계산하는 수식 제시 ※표 참조
- 합성곱 연산(*)과 Hadamard 곱(⊙) 사용
- 커널 크기의 영향:
- 더 큰 전이 커널: 빠른 움직임 포착 가능
- 더 작은 커널: 느린 움직임 포착 가능
- FC-LSTM과의 비교:
- FC-LSTM을 ConvLSTM의 특수한 경우로 볼 수 있음 (모든 특징이 단일 셀에 있는 경우)
- 패딩의 역할:
- 입력과 상태의 크기를 일치시키기 위해 사용
- 경계점에서의 패딩은 "외부 세계의 상태"를 사용하는 것으로 해석 가능
- 제로 패딩: 외부에 대한 사전 지식이 없다고 가정
- 경계 처리의 중요성:
- 경계점을 다르게 처리함으로써 시스템의 특성을 더 잘 포착할 수 있음
- 예: 벽에 부딪히는 공의 움직임 예측

이 구조는 시공간 데이터의 특성을 효과적으로 포착할 수 있도록 설계되었으며, 특히 공간적 지역성과 시간적 의존성을 동시에 모델링할 수 있는 능력을 가지고 있습니다. 이는 강수 nowcasting과 같은 복잡한 시공간 예측 문제에 매우 적합한 접근 방식입니다.
3-2. Encoding-Forecasting Structure
ConvLSTM을 활용한 전체 네트워크 구조를 설명
- 전체 네트워크 구조:
- 인코딩 네트워크와 예측 네트워크로 구성
- 두 네트워크 모두 여러 ConvLSTM 층을 쌓아서 형성
- 네트워크 연결:
- 예측 네트워크의 초기 상태와 셀 출력은 인코딩 네트워크의 마지막 상태에서 복사
- 최종 예측 생성:
- 예측 네트워크의 모든 상태를 연결(concatenate)
- 1x1 합성곱 층을 통해 최종 예측 생성
- 구조 해석:
- 인코딩 LSTM: 전체 입력 시퀀스를 은닉 상태 텐서로 압축
- 예측 LSTM: 이 은닉 상태를 펼쳐 최종 예측 생성
- 수학적 표현:
- 조건부 확률 최대화 문제를 인코딩 함수와 예측 함수의 조합으로 근사 ※표 참조
- 기존 모델과의 차이점:
- LSTM future predictor 모델과 유사하지만, 입력과 출력 요소가 모두 3D 텐서
- 공간 정보를 모두 보존
- 모델의 강점:
- 다중 ConvLSTM 층으로 인한 강력한 표현 능력
- 강수 nowcasting과 같은 복잡한 동적 시스템 예측에 적합



이러한 구조는 강수 nowcasting 문제에 특히 적합하며, 레이더 에코 맵의 복잡한 시공간 패턴을 효과적으로 학습하고 예측할 수 있습니다.
4. Experiments
ConvLSTM 네트워크의 성능 평가 실험과 그 결과에 대해 설명
- 실험 설계:
- Moving-MNIST 데이터셋을 사용한 기초적인 성능 비교
- 실제 레이더 에코 데이터셋을 구축하여 강수 nowcasting 성능 평가
- FC-LSTM 및 ROVER 알고리즘과의 비교
- 실험 변수:
- 레이어 수와 커널 크기를 다양하게 변경하며 실험
- "out-of-domain" 케이스 연구
- 평가 지표:
- 강수 nowcasting에 일반적으로 사용되는 여러 메트릭 사용
- 주요 실험 결과:
- ConvLSTM이 FC-LSTM보다 시공간 상관관계 처리에 우수
- 상태-상태 합성곱 커널 크기가 1보다 큰 것이 시공간 모션 패턴 포착에 중요
- 더 깊은 모델이 더 적은 매개변수로 더 나은 결과 생성
- ConvLSTM이 ROVER보다 강수 nowcasting에서 우수한 성능 달성
- 실험 환경:
- Python과 Theano 사용하여 구현
- NVIDIA K20 GPU 사용
이러한 실험 결과는 ConvLSTM의 여러 장점을 보여줍니다:
- 시공간 데이터 처리 능력: FC-LSTM보다 시공간 상관관계를 더 잘 포착합니다.
- 모션 패턴 포착: 더 큰 합성곱 커널을 사용함으로써 복잡한 모션 패턴을 효과적으로 학습합니다.
- 효율적인 모델 구조: 깊은 구조가 적은 매개변수로도 좋은 성능을 낼 수 있어, 계산 효율성이 높습니다.
- 실제 문제에서의 우수성: 강수 nowcasting과 같은 복잡한 실제 문제에서 기존 방법론보다 우수한 성능을 보입니다.
- 일반화 능력: "out-of-domain" 케이스 연구를 통해 모델의 일반화 능력을 검증했습니다.
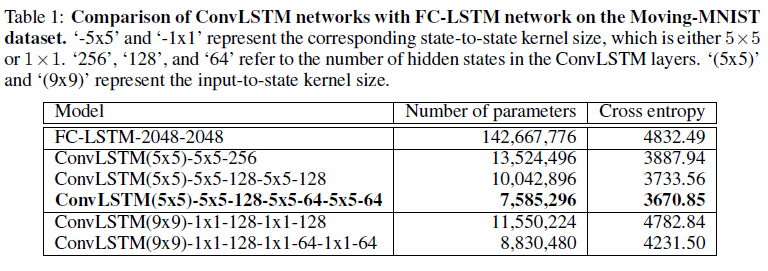
4-1. Moving-MNIST Dataset
Moving-MNIST 데이터셋을 사용한 실험에 대해 설명
- 데이터셋 생성:
- 20프레임 길이 (입력 10프레임, 예측 10프레임)
- 64x64 패치 내에서 두 개의 손글씨 숫자가 움직임
- 15,000개 시퀀스 생성 (훈련 10,000, 검증 2,000, 테스트 3,000)
- 학습 방법:
- 크로스 엔트로피 손실 최소화
- BPTT와 RMSProp 사용 (학습률 10^-3, 감율 0.9)
- 검증 세트를 사용한 조기 중단(early-stopping) 적용
- 모델 구조:
- FC-LSTM: 2개의 2048-노드 LSTM 층
- ConvLSTM: 1-레이어 , 2-레이어 , 3-레이어 변형 테스트
- 1-레이어 네트워크: 256개의 은닉 상태를 가진 1개의 ConvLSTM 레이어.
- 2-레이어 네트워크: 각각 128개의 은닉 상태를 가진 2개의 ConvLSTM 레이어.
- 3-레이어 네트워크: 각각 128, 64, 64개의 은닉 상태를 가진 3개의 ConvLSTM 레이어.
- 입력-상태 및 상태-상태 커널 크기: 5x5
- 기타 구성:
- 2-레이어 네트워크: 커널을 1x1 및 9x9로 변경.
- 3-레이어 네트워크: 더 큰 상태-상태 커널이 있는 네트워크가 더 나은 성능을 보임.
- 실험 결과:
- ConvLSTM이 FC-LSTM보다 일관되게 더 나은 성능 보임
- 더 깊은 모델이 더 나은 결과 제공 ( 2-레이어와 3-레이어 사이의 개선은 크지 않음)
- 상태-상태 커널 크기가 1x1일 때 성능이 크게 저하됨
- 9x9 커널은 더 넓은 범위를 볼 수 있지만, 5x5 커널보다는 성능이 떨어짐
- "Out-of-domain" 테스트:
- 서로 다른 MNIST 숫자 집합에서 무작위로 선택된 숫자 3개로 3,000개의 시퀀스 생성
- 3층 모델의 평균 크로스 엔트로피 오류: 6379.42
- 모델이 겹치는 숫자를 분리하고 전체적인 움직임을 예측할 수 있음을 확인 ※ Fig. 10에 제시됨.
이 실험 결과는 ConvLSTM의 여러 장점을 보여줍니다:
- 시공간 상관관계 처리: FC-LSTM보다 더 효과적으로 시공간 패턴을 포착합니다.
- 모델 깊이의 영향: 더 깊은 모델이 일반적으로 더 나은 성능을 보이지만, 일정 수준 이상에서는 개선 효과가 줄어듭니다.
- 커널 크기의 중요성: 상태-상태 전이에서 1x1보다 큰 커널 크기가 중요하며, 이는 시간이 지남에 따라 수용 영역(receptive field)이 커지는 것과 관련이 있습니다.
- 일반화 능력: "Out-of-domain" 테스트에서도 합리적인 성능을 보여, 모델의 일반화 능력을 확인할 수 있습니다.
이러한 결과는 ConvLSTM이 복잡한 시공간 패턴을 학습하고 예측하는 데 효과적인 모델임을 보여주며, 특히 제한된 훈련 데이터로도 좋은 성능을 낼 수 있음을 시사합니다.


4-2. Radar Echo Dataset
실제 레이더 에코 데이터셋을 사용한 강수 nowcasting 실험에 대해 설명
- 데이터셋 구성
- 2011-2013년 홍콩의 기상 레이더 데이터 중 상위 97개 우천일 선택
- 전처리: 강도 값 Z를 회색 레벨 픽셀 P로 변환:

- 레이더 맵을 중앙 330x330 영역으로 자르고, 디스크 필터(반경 10)를 적용 후 100x100으로 크기 조정
- K-평균 클러스터링을 사용하여 일부 노이즈가 있는 영역의 픽셀 값 제거.
- 모델 구성
- ConvLSTM:
- 구조: 2층 네트워크, 각 층 64개 은닉 상태, 3x3 커널.
- 패치 크기: 2.
- ROVER:
- 광학 흐름 기반 알고리즘.
- 3가지 초기화 방식: ROVER1 (마지막 두 프레임의 광학 흐름 계산 후 반투영 아드벡션), ROVER2 (마지막 두 흐름 필드의 평균으로 초기화), ROVER3 (마지막 세 흐름 필드의 가중 평균으로 초기화).
- FC-LSTM:
- 구조: 2000-노드 LSTM 층 2개.
- 최적화 목표: 15개 예측의 교차 엔트로피 오류 최적화.
- ConvLSTM:
- 평가 지표
- Rainfall-MSE: 예측된 강수량과 실제 값 간의 평균 제곱 오차.
- CSI (Critical Success Index), FAR (False Alarm Rate), POD (Probability of Detection): 예측의 정밀도와 재현율을 나타내는 기술 점수.
- CSI:

- FAR:

- POD:

- CSI:
- 상관관계: 예측 프레임과 실제 프레임 간의 상관관계 계산
- 실험 결과
- ConvLSTM:
- 우수한 성능: ROVER와 FC-LSTM보다 성능이 우수함.
- 경계 조건 처리: 경계에서 갑작스러운 구름 형성을 잘 처리함.
- 복잡한 패턴 학습: 비선형 및 합성곱 구조로 복잡한 시공간 패턴을 효과적으로 학습함.
- 엔드-투-엔드 학습: 전체 시스템을 한 번에 최적화하여 효과적임.
- FC-LSTM:
- 성능 한계: 레이더 맵의 강한 공간적 상관관계를 포착하기 어려움.
- ROVER:
- 선명한 예측: 더 선명한 예측을 제공하지만 오경보가 많고 전반적으로 정확도가 낮음.
- ConvLSTM과의 비교: ConvLSTM이 미래 강수 윤곽을 더 정확하게 예측, 특히 경계 부분에서 우수함.
- ConvLSTM:
- 시각적 결과 분석
- ConvLSTM이 미래 강수 윤곽을 더 정확하게 예측, 특히 경계 부분에서 우수함.
- ROVER는 더 선명한 예측을 제공하지만, 더 많은 거짓 경고를 발생시키며 전반적으로 정확도가 낮음.
- ConvLSTM의 흐림 효과는 장기 예측에서의 본질적 불확실성을 반영할 수 있음


이 실험 결과는 ConvLSTM의 여러 장점을 강조합니다:
- 공간적 일관성 포착: 레이더 맵의 지역적 일관성을 효과적으로 학습합니다.
- 경계 조건 처리: 갑작스러운 구름 형성과 같은 경계 현상을 잘 처리합니다.
- 복잡한 패턴 학습: 비선형적이고 합성곱적인 구조로 복잡한 시공간 패턴을 학습합니다.
- 엔드-투-엔드 학습: 전체 시스템을 한 번에 최적화할 수 있어 효과적입니다.
- 불확실성 처리: 장기 예측의 본질적 불확실성을 흐림 효과로 표현합니다.
- 성능 우수성: 이러한 특성 덕분에 ConvLSTM은 기상 예측 문제에서 기존 방법론들보다 우수한 성능을 보일 수 있습니다.
- 복잡한 시공간 패턴 처리: 특히 복잡한 시공간 패턴을 포함하는 문제에서 ConvLSTM의 강점이 두드러집니다.
5. Conclusion and Future Work
논문의 주요 내용과 기여를 요약하고 있으며, 향후 연구 방향을 제시
- 연구의 의의:
- 기계학습, 특히 딥러닝을 강수 nowcasting 문제에 성공적으로 적용
- 이전에는 정교한 기계학습 기법의 혜택을 받지 못했던 분야에 혁신적 접근
- 문제 정의:
- 강수 nowcasting을 시공간 시퀀스 예측 문제로 공식화
- 제안 모델: ConvLSTM
- LSTM의 새로운 확장 버전
- FC-LSTM의 장점 유지
- 내재된 합성곱 구조로 시공간 데이터에 적합
- 모델 구조:
- ConvLSTM을 인코딩-예측 구조에 통합
- 강수 nowcasting을 위한 end-to-end 학습 가능 모델 구축
- 향후 연구 방향:
- ConvLSTM을 비디오 기반 행동 인식에 적용하는 방법 연구
- 제안된 아이디어: 합성곱 신경망으로 생성된 공간 특징 맵 위에 ConvLSTM 추가
- ConvLSTM의 은닉 상태를 최종 분류에 사용
Reference
논문 출저: Convolutional LSTM Network: A Machine Learning Approach for Precipitation Nowcasting
'논문 리뷰' 카테고리의 다른 글
| [논문 리뷰] Efficient Estimation of Word Representations in Vector Space (2) | 2024.10.05 |
|---|---|
| [논문 리뷰] ImageNet Classification with Deep Convolutional Neural Networks (1) | 2024.10.05 |
| 논문리뷰 SSD: Single Shot MultiBox Detector (1) | 2024.08.05 |
| [논문 리뷰] BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding (0) | 2024.07.08 |
| [논문 리뷰] Attention Is All You Need (0) | 2024.07.08 |



