이 논문은 "BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding"이라는 제목의 논문입니다.
작성자는 Jacob Devlin, Kenton Lee, Kristina Toutanova, 그리고 Ming-Wei Chang 이며, 2018년에 발표된 해당 논문은 왼쪽과 오른쪽 문맥을 모두 고려하는 양방향의 인코더를 가진 사전학습 모형, BERT를 제시합니다.
Abstract
이 논문의 주요 내용을 요약하면 다음과 같습니다:
- BERT(Bidirectional Encoder Representations from Transformers)라는 새로운 언어 표현 모델을 소개합니다.
- BERT는 모든 계층에서 좌우 문맥을 동시에 고려하여 레이블이 없는 텍스트로부터 심층적 양방향 표현을 사전 학습하도록 설계되었습니다.
- 사전 학습된 BERT 모델은 출력 레이어 하나만 추가하여 미세 조정할 수 있어, 다양한 작업에 대해 최첨단 모델을 만들 수 있습니다.
- 11개의 자연어 처리 작업에서 새로운 최고 성능을 달성했습니다. 예를 들어:
- GLUE 점수를 80.5%로 향상 (7.7% 포인트 절대 개선)
- MultiNLI 정확도를 86.7%로 향상 (4.6% 절대 개선)
- SQuAD v1.1 질문 답변 테스트 F1 점수를 93.2로 향상 (1.5 포인트 절대 개선)
- SQuAD v2.0 테스트 F1 점수를 83.1로 향상 (5.1 포인트 절대 개선)
요약하면, 이 논문은 문맥을 고려한 단어 표현의 중요성을 강조하며, 이를 위한 새로운 방법으로 BERT 모델을 제안합니다. 또한, 자연어 처리(NLP) 분야에서 다양한 작업에서 성능을 크게 향상시킬 수 있음을 실험적으로 입증합니다.
1. Introduction
- 배경: 언어 모델 사전 훈련은 자연어 처리 작업에서 자연어 추론, 패러프레이징, 개체명 인식, 질문 응답 등을 향상시키는 데 효과적으로 사용되어 왔습니다.
- 기존 접근 방식의 한계: 기존의 단방향 언어 모델을 사용하는 접근 방식은 양방향 문맥을 충분히 고려하지 못하는 한계가 있습니다.
- BERT 모델: BERT는 양방향 인코더 표현을 사용하여 이러한 한계를 극복하고, 마스크 언어 모델 (MLM)과 다음 문장 예측을 통해 깊이 있는 언어 이해를 가능하게 합니다.
- BERT의 특징:
- 마스크 언어 모델 (MLM) 사용: 무작위로 일부 토큰을 마스킹하여 언어 모델을 사전 학습함으로써 문맥을 통합적으로 학습합니다.
- 다음 문장 예측(NSP): 문장 쌍 사이의 관계를 학습하여 언어 이해 능력을 더욱 향상시킵니다.
- BERT의 기여:
- 양방향 사전 학습의 중요성 입증: BERT는 양방향 사전 학습이 NLP 작업에서 성능을 크게 향상시키는 것을 입증합니다.
- 작업별 특화 아키텍처의 필요성 감소: 단일 모델로 다양한 자연어 처리 작업에 적용 가능하여, 복잡한 작업별 특화 아키텍처가 필요하지 않도록 합니다.
- 다양한 NLP 작업에서 최고 성능 달성: BERT는 다양한 NLP 벤치마크에서 최고 성능을 기록하여 모델의 강력함을 입증합니다.
2. Related Work
일반 언어 표현 사전 훈련의 장기적인 역사에 대해 가장 널리 사용된 접근 방식들을 확인해보겠습니다.
2-1. Unsupervised Feature-based Approaches
단어 표현 학습의 역사와 발전에 대해 설명합니다.
- 단어 표현 학습의 역사:
- 수십 년간 활발한 연구 영역
- 비신경망 방식(Brown et al., 1992; Ando and Zhang, 2005; Blitzer et al., 2006)과 신경망 방식(Mikolov et al., 2013; Pennington et al., 2014) 모두 포함
- 사전 학습된 단어 임베딩의 중요성:
- 현대 NLP 시스템의 핵심 요소
- 처음부터 학습한 임베딩보다 큰 성능 향상(Turian et al., 2010)
- 단어 임베딩 사전 학습 방법:
- 왼쪽에서 오른쪽으로의 언어 모델링 목표 사용(Mnih and Hinton, 2009)
- 좌우 문맥에서 올바른 단어와 잘못된 단어를 구별하는 목표(Mikolov et al., 2013)
- 문장 및 단락 수준으로의 확장:
- 문장 임베딩(Kiros et al., 2015; Logeswaran and Lee, 2018), 단락 임베딩(Le and Mikolov, 2014)으로 일반화
- 다음 문장 예측(Jernite et al., 2017; Logeswaran and Lee, 2018), 자기부호화기(Hill et al., 2016) 등 다양한 학습 목표 사용
- ELMo의 특징:
- 문맥 의존적 특성 추출
- 왼쪽에서 오른쪽, 오른쪽에서 왼쪽 언어 모델 사용
- 여러 NLP 벤치마크에서 최고 성능 달성 (Peters et al., 2018a)
- 관련 연구:
- Melamud et al.의 LSTM 기반 문맥 표현 학습 (Melamud et al., 2016)
- Fedus et al.의 빈칸 채우기 과제를 통한 텍스트 생성 모델 개선 (Fedus et al., 2018)
이 섹션은 단어 표현 학습 분야의 발전 과정과 주요 접근 방식들을 포괄적으로 설명하고 있으며, 특히 ELMo와 같은 문맥 기반 표현 학습의 중요성을 강조하고 있습니다.
2-2. Unsupervised Fine-tuning Approaches
자연어 처리에서 사전 학습과 미세 조정 접근법의 발전에 대해 설명하고 있습니다.
- 초기 접근법:
- 레이블이 없는 텍스트로부터 단어 임베딩 파라미터만 사전 학습
- 최근의 발전:
- 문장 또는 문서 인코더를 레이블이 없는 텍스트로 사전 학습
- 지도 학습 기반의 하위 작업을 위해 미세 조정
- 이 접근법의 장점:
- 처음부터 학습해야 할 파라미터가 적음
- 이로 인해 많은 문장 수준 작업에서 최고 성능 달성 (예: OpenAI GPT)
- 사전 학습에 사용된 목표:
- 왼쪽에서 오른쪽으로의 언어 모델링
- 자기부호화기 목표
- 성과:
- OpenAI GPT가 GLUE 벤치마크의 많은 문장 수준 작업에서 최고 성능 달성
이 섹션은 자연어 처리 모델의 사전 학습과 미세 조정 접근법의 발전 및 효과성을 설명하며, 특히 OpenAI GPT의 성공으로 그 효용성을 강조합니다.
2-3. Transfer Learning from Supervised Data
전이 학습의 효과성에 대해 설명하고 있으며, 자연어 처리와 컴퓨터 비전 분야의 예시를 들고 있습니다.
- 대규모 지도 학습 데이터셋을 활용한 전이 학습:
- 자연어 추론(Natural Language Inference)과 기계 번역(Machine Translation) 분야에서 효과적인 전이 학습 사례 언급
- 구체적인 연구 사례:
- Conneau et al. (2017): 자연어 추론 관련 연구
- McCann et al. (2017): 기계 번역 관련 연구
- 컴퓨터 비전 분야의 전이 학습:
- 대규모 사전 학습 모델의 중요성 입증
- ImageNet으로 사전 학습된 모델을 미세 조정하는 것이 효과적인 방법으로 언급
- 관련 연구:
- Deng et al. (2009): ImageNet 관련 연구
- Yosinski et al. (2014): 전이 학습 관련 연구
이 섹션은 자연어 처리와 컴퓨터 비전 분야 모두에서 대규모 데이터셋으로 사전 학습된 모델을 활용한 전이 학습이 효과적임을 강조하고 있습니다.
3. BERT
텍스트는 BERT (Bidirectional Encoder Representations from Transformers) 모델에 대해 상세히 설명하고 있습니다.
- BERT의 프레임워크:
- 사전 학습 단계: 레이블이 없는 데이터로 다양한 사전 학습 작업을 수행합니다.
- 미세 조정 단계: 사전 학습된 파라미터로 초기화한 후, 각 하위 작업별 레이블 데이터로 모델을 미세 조정합니다.
- BERT의 특징:
- 다양한 작업에 대해 통합된 아키텍처를 사용하며, 사전 학습 아키텍처와 하위 작업 아키텍처 간의 차이를 최소화합니다.
- 모델 아키텍처:
- 다층 양방향 Transformer 인코더를 기반으로 합니다.
- 두 가지 모델 크기인 BERTBASE와 BERTLARGE가 있습니다.
- 입력/출력 표현:
- 단일 문장과 문장 쌍을 모두 처리할 수 있습니다.
- 30,000 토큰 어휘를 사용하는 WordPiece 임베딩을 사용합니다.
- 특수 분류 토큰 [CLS]와 문장 구분 토큰 [SEP]을 사용합니다.
- 각 입력 토큰은 토큰, 세그먼트, 위치 임베딩의 합으로 구성됩니다.
- 문장 처리:
- "문장"은 실제 언어학적 문장이 아니라 연속된 텍스트의 임의의 범위를 의미합니다.
- 문장 쌍은 하나의 시퀀스로 결합됩니다.
- 토큰 표현:
- [CLS] 토큰의 최종 은닉 상태를 분류 작업에 사용하며, 각 입력 토큰에 대한 최종 은닉 벡터를 생성합니다.

이 섹션은 BERT의 구조와 작동 방식, 그리고 다양한 NLP 작업 처리 방법을 상세히 설명하며, BERT의 효과적인 다용도 활용을 보여줍니다.
3-1. Pre-training BERT
BERT의 사전 학습 방법에 대해 자세히 설명합니다.
- 전통적인 언어 모델 대신 비지도 학습 작업 사용:
- BERT는 전통적인 왼쪽에서 오른쪽 또는 오른쪽에서 왼쪽 언어 모델 대신 두 가지 비지도 학습 작업을 사용하여 사전 학습됩니다.
- 작업 #1: 마스크 언어 모델 (Masked LM, MLM):
- 입력 토큰의 일부를 무작위로 마스크하고, 이를 예측하는 작업입니다.
- 각 시퀀스에서 15%의 WordPiece 토큰이 마스크됩니다.
- 마스크된 토큰은 다음과 같이 처리됩니다:
- 80%는 [MASK] 토큰으로 대체됩니다.
- 10%는 무작위로 선택된 다른 토큰으로 대체됩니다.
- 10%는 원래 토큰을 그대로 유지합니다.
- 교차 엔트로피 손실을 사용하여 마스크된 토큰의 원래 값을 예측합니다.
- 작업 #2: 다음 문장 예측 (Next Sentence Prediction, NSP):
- 두 문장 간의 관계를 이해하기 위한 이진 분류 작업입니다.
- 각 사전 학습 예제에서 두 문장 A와 B가 있을 때:
- 50%는 B가 실제로 A의 다음 문장(IsNext)인 경우입니다.
- 50%는 B가 코퍼스에서 무작위로 선택된 다른 문장(NotNext)인 경우입니다.
- NSP 작업은 QA(Question Answering) 및 NLI(Natural Language Inference)와 같은 하위 작업에 매우 유용합니다.
- 사전 학습 데이터:
- BERT는 BooksCorpus (800M 단어)와 영어 위키피디아 (2,500M 단어)와 같은 대규모 텍스트 데이터를 사용하여 사전 학습됩니다.
- 위키피디아에서는 텍스트 구절만을 추출하고, 목록, 표, 헤더 등은 제외됩니다.
- 문서 수준 코퍼스를 사용하여 긴 연속적인 시퀀스를 추출하는 것이 중요합니다.
- 기존 방법과의 차이점:
- BERT는 양방향 표현 학습을 가능하게 합니다.
- 사전 학습과 미세 조정 사이의 불일치 문제를 해결하기 위해 다양한 접근 방식을 시도합니다.
- 모든 파라미터가 하위 작업 모델 파라미터 초기화에 사용됩니다.
이 섹션에서는 BERT는 더 깊고 강력한 양방향 표현을 학습할 수 있으며, 다양한 하위 작업에 효과적으로 적용될 수 있습을 보여줍니다.
3-2. Fine-tuning BERT
BERT의 미세 조정(fine-tuning) 과정에 대해 설명합니다.
- 미세 조정의 간단함:
- Transformer의 자기 주의 메커니즘 덕분에 다양한 하위 작업에 쉽게 적용 가능합니다.
- 단일 텍스트나 텍스트 쌍을 모두 처리할 수 있습니다.
- 텍스트 쌍 처리 방식:
- 기존 방법: 독립적으로 인코딩 후 양방향 교차 주의를 적용합니다.
- BERT 방법: 자기 주의 메커니즘을 사용하여 두 단계를 통합합니다.
- 작업별 적용 방법:
- 각 작업에 맞는 입력과 출력을 BERT에 연결하여 모든 파라미터를 end-to-end로 미세 조정합니다.
- 예시:
- 패러프레이징: 문장 쌍
- 함의: 가설-전제 쌍
- 질문 답변: 질문-구절 쌍
- 텍스트 분류/시퀀스 태깅: 텍스트-∅(빈칸) 쌍
- 입력 구조:
- 사전 학습에서 사용된 문장 A와 B를 각 작업에 적용하여 입력 구조를 유지합니다.
- 출력 처리:
- 토큰 수준 작업에서는 각 토큰의 표현을 출력 레이어로 전달합니다.
- 분류 작업에서는 [CLS] 토큰의 표현을 출력 레이어로 전달합니다.
- 미세 조정의 효율성:
- 사전 학습에 비해 미세 조정이 비교적 저렴합니다.
- 대부분의 실험 결과를 클라우드 TPU에서 1시간 이내 또는 GPU에서 몇 시간 내에 복제할 수 있습니다.
이 섹션은 BERT의 미세 조정 과정에 대한 핵심 요소들을 보여줍니다.
4. Experiments
이 섹션에서는 11가지 NLP 작업에 대한 BERT 미세 조정 결과를 보여줍니다 .
4-1. GLUE
BERT의 GLUE (General Language Understanding Evaluation) 벤치마크에서의 성능에 대해 설명합니다.
- GLUE 벤치마크:
- 다양한 자연어 이해 작업의 집합
- 상세 설명은 논문의 부록 B.1에 포함
- GLUE에서의 미세 조정 방법:
- 입력 시퀀스를 Section 3에서 설명한 대로 표현
- [CLS] 토큰에 해당하는 최종 은닉 벡터 C를 집계 표현으로 사용
- 새로 도입된 파라미터는 분류 레이어 가중치 W뿐임
- 표준 분류 손실 함수 사용: log(softmax(CWT))
- 미세 조정 세부 사항:
- 배치 크기 32, 3 에폭 동안 미세 조정
- 최적의 학습률을 Dev 세트에서 선택 (5e-5, 4e-5, 3e-5, 2e-5 중)
- BERTLARGE의 경우 작은 데이터셋에서 불안정할 때 여러 번의 무작위 재시작 수행
- 결과:
- BERTBASE와 BERTLARGE 모두 모든 작업에서 기존 최고 성능을 크게 상회
- 평균 정확도 개선: BERTBASE 4.5%, BERTLARGE 7.0%
- MNLI 작업에서 4.6% 절대 정확도 향상
- GLUE 리더보드에서 BERTLARGE 80.5점 달성 (OpenAI GPT 72.8점)
- 모델 크기의 영향:
- BERTLARGE가 BERTBASE보다 모든 작업에서 크게 우수한 성능
- 특히 훈련 데이터가 적은 작업에서 더 큰 차이
- OpenAI GPT와의 비교:
- BERTBASE와 OpenAI GPT는 주의 마스킹을 제외하고 모델 구조가 거의 동일
- 그럼에도 BERT가 훨씬 우수한 성능 달성
이 섹션에서 BERT는 다양한 자연어 이해 작업에서 뛰어난 성능을 보이며, 특히 모델 크기가 클수록 성능이 더욱 좋다는것을 보여줍니다.
4-2. SQuAD v1.1
BERT를 Stanford Question Answering Dataset (SQuAD v1.1)에 적용한 결과에 대해 설명합니다.
- SQuAD v1.1:
- 100k개의 크라우드소싱된 질문/답변 쌍 포함
- 위키피디아 구절에서 주어진 질문에 대한 답변 텍스트 범위 예측
- BERT의 입력 처리:
- 질문과 구절을 단일 시퀀스로 결합
- 질문은 A 임베딩, 구절은 B 임베딩 사용
- 미세 조정 방법:
- 시작 벡터 S와 끝 벡터 E 도입
- 답변 범위의 시작과 끝 확률을 소프트맥스로 계산
- 후보 범위 점수: S·Ti + E·Tj
- 학습 목표: 정확한 시작과 끝 위치의 로그 우도 합
- 학습 세부 사항:
- 3개의 에폭 동안 미세 조정
- 학습률 5e-5, 배치 크기 32
- 결과:
- 리더보드 상위 항목 및 주요 발표 시스템과 비교
- BERT 최고 성능 시스템:
- 앙상블: 리더보드 최상위 시스템보다 +1.5 F1 향상
- 단일 시스템: +1.3 F1 향상
- 단일 BERT 모델이 최고 앙상블 시스템의 F1 점수 상회
- 데이터 증강:
- TriviaQA로 먼저 미세 조정 후 SQuAD에 미세 조정
- TriviaQA 없이도 0.1-0.4 F1만 손실, 여전히 기존 시스템들 크게 상회
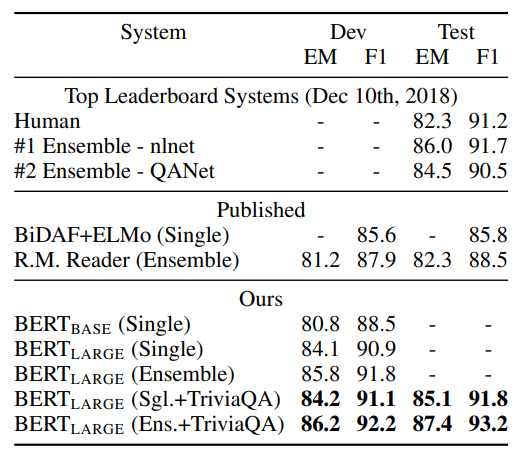
이 섹션에서는 BERT가 고급 아키텍처와 미세 조정 전략을 통해 SQuAD 데이터 세트에서 최고 성능을 달성하는 효과를 보여줍니다.
4-3. SQuAD v2.0
BERT를 SQuAD 2.0 작업에 적용한 방법과 결과에 대해 설명합니다.
- SQuAD 2.0:
- SQuAD 1.1을 확장한 버전
- 주어진 단락에 짧은 답변이 없을 가능성 포함
- 더 현실적인 문제 설정
- BERT 모델 확장 방법:
- 답변이 없는 질문을 [CLS] 토큰에 시작과 끝이 있는 답변 범위로 취급
- 답변 범위의 시작과 끝 위치 확률 공간을 [CLS] 토큰 위치를 포함하도록 확장
- 예측 방법:
- 무답변 범위 점수(snull)와 최고 답변 범위 점수(sˆi,j) 비교
- sˆi,j > snull + τ 일 때 답변 있음으로 예측
- 임계값 τ는 개발 세트에서 F1 점수를 최대화하도록 선택
- 학습 세부 사항:
- TriviaQA 데이터 미사용
- 2 에폭 동안 미세 조정
- 학습률 5e-5, 배치 크기 48
- 결과:
- 이전 리더보드 항목 및 주요 발표 논문과 비교
- BERT를 구성 요소로 사용하는 시스템은 제외
- 이전 최고 시스템 대비 +5.1 F1 점수 향상
이 섹션은 BERT가 SQuAD 2.0과 같은 더 복잡한 질문 답변 작업에서도 탁월한 성능을 보이며, 답변이 없는 경우도 처리하는것을 보여줍니다.
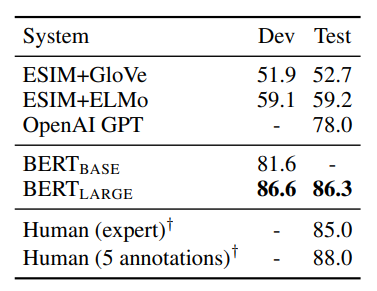
4-4. SWAG
BERT를 Situations With Adversarial Generations (SWAG) 데이터셋에 적용한 방법과 결과에 대해 설명합니다.
- SWAG 데이터셋 소개:
- 113k개의 문장-쌍 완성 예제 포함
- 상식적 추론 능력 평가 목적
- 주어진 문장에 대해 가장 그럴듯한 연속 문장을 4개 선택지 중에서 고르는 작업
- BERT 적용 방법:
- 4개의 입력 시퀀스 구성
- 각 시퀀스는 주어진 문장(A)과 가능한 연속 문장(B)의 연결로 구성
- 작업별 추가 파라미터: [CLS] 토큰 표현과의 내적을 통해 각 선택지의 점수를 계산하는 벡터
- 소프트맥스 층을 통해 점수 정규화
- 미세 조정 세부 사항:
- 3 에폭 동안 미세 조정
- 학습률 2e-5
- 배치 크기 16
- 결과(BERTLARGE의 성능):
- 저자들의 기준선 시스템(ESIM+ELMo)보다 27.1% 향상
- OpenAI GPT보다 8.3% 향상
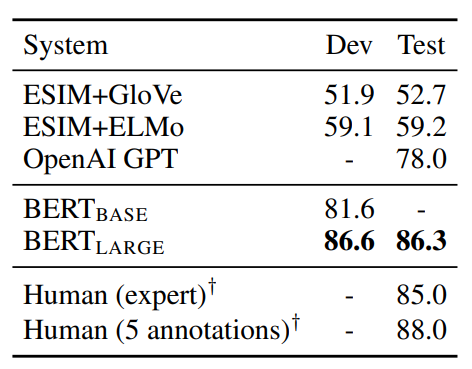
이 섹션은 BERT가 단순한 언어 이해를 넘어 상식적 추론과 같은 더 복잡한 인지 작업에서도 탁월한 성능을 보여줍니다.
5. Ablation Studies
BERT 모델의 다양한 측면에 대한 절제 실험(ablation experiments)을 소개합니다.
5-1. Effect of Pre-training Tasks
BERT 모델의 깊은 양방향성(deep bidirectionality)의 중요성을 평가하기 위한 실험에 대해 설명합니다.
- 실험 설계:
- BERTBASE와 동일한 사전 학습 데이터, 미세 조정 방식, 하이퍼파라미터 사용
- 두 가지 사전 학습 목표 평가:
- No NSP: 마스크 언어 모델(MLM)만 사용, 다음 문장 예측(NSP) 제거
- LTR & No NSP: 왼쪽-오른쪽(LTR) 언어 모델 사용, NSP 제거
- NSP 작업의 영향:
- NSP 제거 시 QNLI, MNLI, SQuAD 1.1에서 성능 현저히 저하
- 양방향 표현의 영향:
- LTR 모델이 모든 작업에서 MLM 모델보다 성능 저하
- MRPC와 SQuAD에서 특히 큰 성능 하락
- LTR 모델 개선 시도:
- 무작위 초기화된 BiLSTM 추가
- SQuAD에서 성능 개선되나 여전히 양방향 모델에 비해 열등
- GLUE 작업에서는 오히려 성능 저하
- ELMo 스타일 접근 방식 고려:
- LTR과 RTL 모델을 별도로 훈련하여 연결하는 방식
- 단점:
- 단일 양방향 모델보다 2배 비용
- QA와 같은 작업에 비직관적
- 깊은 양방향 모델보다 표현력 제한
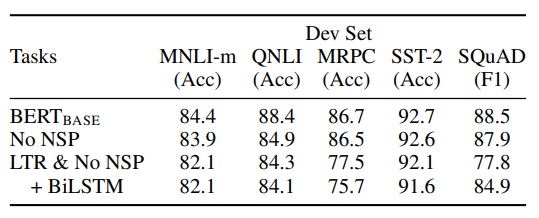
이 섹션은 BERT의 실험 결과는 깊은 양방향성이 모델 성능에 중요한 요소임을 보여줍니다.
5-2. Effect of Model Size
BERT 모델의 크기가 미세 조정 작업의 정확도에 미치는 영향을 탐구한 실험에 대해 설명합니다.
- 실험 설계:
- 다양한 층 수, 은닉 유닛 수, 주의 헤드 수를 가진 BERT 모델들을 훈련
- 다른 하이퍼파라미터와 훈련 절차는 동일하게 유지
- 결과:
- 모든 데이터셋에서 더 큰 모델이 정확도 향상을 보임
- MRPC와 같은 작은 데이터셋(3,600 레이블된 훈련 예제)에서도 개선 효과 관찰
- 모델 크기 비교:
- BERTBASE: 110M 파라미터
- BERTLARGE: 340M 파라미터
- 기존 최대 Transformer 모델들보다 훨씬 큰 규모
- 주요 발견:
- 대규모 작업(기계 번역, 언어 모델링)뿐만 아니라 소규모 작업에서도 모델 크기 증가가 성능 향상으로 이어짐
- 충분한 사전 학습이 이루어진 경우, 극단적인 모델 크기 확장이 매우 작은 규모의 작업에서도 큰 개선을 가져옴
- 기존 연구와의 차이:
- 이전 연구들은 모델 크기 증가의 효과에 대해 혼재된 결과를 보였습니다.
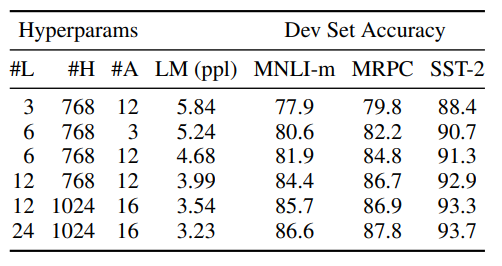
이 섹션은 BERT와 같은 대규모 언어 모델에서 모델 크기 증가가 다양한 규모의 NLP 작업에서 일관된 성능 향상을 가져오는 것 보여줍니다.
5-3. Feature-based Approach with BERT
BERT의 미세 조정(fine-tuning) 접근법과 특성 기반(feature-based) 접근법을 비교한 내용을 보여줍니다.
- 두 가지 접근 방식 소개:
- 미세 조정 방식: 사전 학습된 모델에 간단한 분류 층을 추가하고 모든 파라미터를 함께 조정
- 특징 기반 방식: 사전 학습된 모델에서 고정된 특징을 추출하여 사용
- 특징 기반 방식의 장점:
- 일부 작업에 더 적합한 특정 모델 구조 사용 가능
- 계산 효율성: 비용이 많이 드는 표현을 한 번만 계산하고 재사용 가능
- NER 작업에 대한 실험 설계:
- CoNLL-2003 데이터셋 사용
- 대소문자 구분 WordPiece 모델 사용
- 태깅 작업으로 공식화, CRF 층 미사용
- 첫 번째 서브토큰의 표현을 분류기 입력으로 사용
- 특징 기반 접근 방식 실험:
- BERT의 파라미터를 조정하지 않고 하나 이상의 층에서 활성화 추출
- 문맥적 임베딩을 two-layer 768-dimensional BiLSTM의 입력으로 사용
- 결과:
- BERTLARGE가 최신 방법들과 경쟁력 있는 성능 보임
- 최상의 성능: 상위 4개 은닉 층의 토큰 표현을 연결하여 사용
- 이 방법이 전체 모델을 미세 조정한 것보다 0.3 F1 점수 낮음
- 결론:
- BERT는 미세 조정 방식과 특 기반 방식 모두에서 효과적
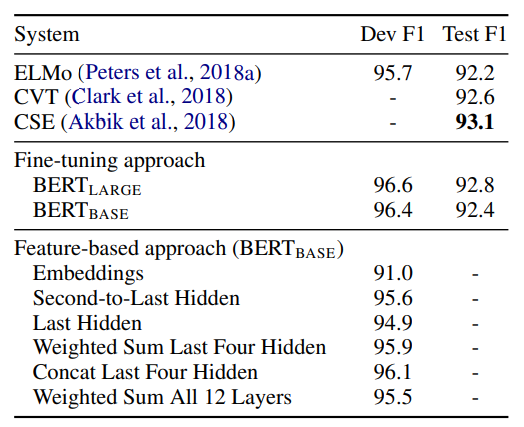
이 섹션은 BERT의 두 가지 접근법에서도 뛰어난 성능을 발휘하는 것을 보여줍니다.
6. Conclusion
- 최근의 경험적 개선:
- 언어 모델을 사용한 전이 학습이 큰 성과를 보임
- 풍부하고 비지도적인 사전 학습이 많은 언어 이해 시스템의 핵심 부분임을 입증
- low-resource 작업에 대한 영향:
- 심층 단방향 아키텍처의 이점을 저자원 작업에도 적용 가능
- BERT의 주요 기여:
- 이러한 발견을 심층 양방향 아키텍처로 일반화
- 동일한 사전 학습 모델을 다양한 NLP 작업에 성공적으로 적용 가능
Reference
논문 출저: BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
'논문 리뷰' 카테고리의 다른 글
| [논문 리뷰] Convolutional LSTM Network: A Machine LearningApproach for Precipitation Nowcasting (1) | 2024.08.12 |
|---|---|
| 논문리뷰 SSD: Single Shot MultiBox Detector (1) | 2024.08.05 |
| [논문 리뷰] Attention Is All You Need (0) | 2024.07.08 |
| [논문 리뷰] Deep contextualized word representations (0) | 2024.07.08 |
| [논문 리뷰] Effective Approaches to Attention-based Neural Machine Translation (0) | 2024.07.01 |



