이 논문은 "Unsupervised Visual Representation Learning by Context Prediction"라는 제목으로, Carl Doersch 외 2명이 2015년에 발표한 연구입니다. 연구진은 이미지 내 패치들 간의 상대적 위치 관계를 학습하는 방법을 통해, 라벨 없이도 이미지의 유의미한 시각적 특징을 추출할 수 있는 비지도 학습 기법을 제시했습니다. 이 방법은 특히 값비싼 레이블링 작업 없이도 효과적인 시각적 특징 학습이 가능하다는 점에서 큰 혁신을 보여주었습니다.
Abstract
이 논문의 주요 내용을 요약하면 다음과 같습니다:
- 연구 목적
- 공간적 맥락(spatial context)을 활용한 시각적 표현(visual representation) 학습
- 레이블이 없는(unlabeled) 이미지 데이터만을 사용한 학습 방법 제시
- 제안하는 방법
- 각 이미지에서 임의의 패치 쌍을 추출
- CNN을 사용하여 첫 번째 패치에 대한 두 번째 패치의 상대적 위치를 예측하도록 학습
- 이 작업을 잘 수행하기 위해서는 모델이 객체와 그 부분들을 인식할 수 있어야 함
- 주요 성과
- 이미지 내 맥락을 통해 학습된 특징 표현이 이미지 간의 시각적 유사성을 포착
- Pascal VOC 2011 데이터셋에서 고양이, 사람, 새와 같은 객체들의 비지도 시각적 발견 가능
- RCNN 프레임워크에서 활용 가능
- 성능
- 무작위 초기화된 CNN보다 훨씬 우수한 성능 달성
- Pascal 데이터셋의 훈련 세트 주석만을 사용하는 알고리즘들 중 최고 성능 달성
1. Introduction

이 내용은 대규모 이미지 데이터셋의 라벨링 비용 문제를 해결하기 위해, 자기지도학습(self-supervised learning) 방식을 제안하는 연구 논문입니다.
- 배경과 문제점:
- 최근 컴퓨터 비전은 수백만 개의 라벨링된 데이터셋으로 학습하여 좋은 성능을 보임
- 하지만 인터넷 규모(수천억 개의 이미지)로 확장하기에는 인력 라벨링 비용이 너무 큰 문제
- 비지도 학습이 대안이 될 수 있으나, 라벨 없이 실제 이미지에서 유용한 정보를 추출하기 어려움
- 제안하는 해결책:
- 텍스트 도메인에서 사용된 "자기지도학습(self-supervised learning)" 방식을 이미지에 적용
- 이미지의 두 패치(patch)간의 상대적 위치를 예측하는 작업을 통해 학습
- 8가지 공간 구성에서 무작위로 추출한 패치 쌍의 관계를 예측하도록 함
- 기대효과:
- 이 작업을 잘 수행하기 위해서는 장면과 객체에 대한 이해가 필요
- 객체는 독립적으로 감지될 수 있는 여러 부분들이 특정 공간 구성을 이루고 있음
- 실험 결과:
- ConvNet 기반 접근법으로 시각적 표현을 학습
- PASCAL VOC2007 객체 탐지 작업에서 성능 향상
- 비지도 객체 발견/시각적 데이터 마이닝에도 효과적
- 단일 이미지 기반 학습임에도 카테고리 수준의 작업에서 일반화 성능을 보임
이 설명은 이미지의 두 패치 간의 상대적 위치 관계를 예측하는 작업을 통해, 라벨링 없이도 효과적인 시각적 표현을 학습할 수 있다는 새로운 방법론을 제시하고 있습니다.
2. Related Work
이 내용은 비지도 학습(unsupervised learning)과 표현 학습(representation learning)에 관한 다양한 기존 연구들을 소개하고 비교 분석하는 논문의 관련 연구(related work) 부분입니다.
- 생성 모델 접근법:
- 자연 이미지의 잠재 변수를 찾는 방식
- 단순한 모델에서도 추론이 어려운 문제
- 손글씨 데이터에서는 성공했으나 고해상도 자연 이미지에는 효과적이지 못함
- 임베딩 학습 접근법:
- "pretext" 과제를 통한 학습 방식
- 디노이징 오토인코더, 희소 오토인코더 등의 방법
- 텍스트 도메인의 "skip-gram" 모델처럼 문맥 예측 과제 활용 (Figure 2)
- 객체 카테고리 발견 접근법:
- 수작업 특징과 클러스터링 활용
- 형태 정보 기반 표현 학습
- 기하학적 검증 방법
- 비디오 활용 접근법:
- 시간적 일관성을 활용한 학습
- 객체의 정체성이 시간에 따라 불변함을 활용
- 판별적 패치 마이닝:
- 약한 지도 학습을 통한 객체 발견
- 장면 수준의 라벨을 pretext 과제로 활용
이 설명은 다양한 이미지 생성 및 표현 학습 방식을 다루고 있으며, 고해상도 자연 이미지에 적용할 수 있는 방법들을 탐구하고 있습니다.
3. Learning Visual Context Prediction
이 내용은 이미지 패치들의 상대적 위치를 예측하는 pretext 과제를 위한 구체적인 ConvNet 아키텍처 설계 방법을 설명하는 부분입니다.
- 학습 목표
- 이미지 내 패치들의 상대적 위치를 예측하는 pretext task를 위한 이미지 표현 학습
- CNN을 사용하여 최소한의 수작업 특징 설계로 복잡한 이미지 표현 학습
- 기본 네트워크 구조
- 두 개의 입력 패치를 여러 컨볼루션 레이어를 통해 처리
- 8가지 공간 구성에 대한 확률을 softmax 출력으로 생성 (Figure 2)
- Late-fusion 아키텍처의 특징 (Figure 3)
- AlexNet 스타일의 아키텍처를 기반으로 함
- 각 패치를 독립적으로 처리하는 두 개의 병렬 네트워크
- fc6 수준까지 독립적으로 처리한 후 표현을 융합
- 양쪽 네트워크의 가중치를 공유하여 동일한 fc6 수준의 임베딩 함수 계산
- 설계 의도
- 시각적으로 유사한 패치들이 임베딩 공간에서 가까워지도록 설계
- 제한된 joint reasoning 용량 (두 개의 레이어만 양쪽 패치 정보 받음)
- 대부분의 의미적 추론을 각 패치별로 독립적으로 수행
- 학습 데이터 생성 방법
- 첫 번째 패치는 이미지 내용과 무관하게 균일하게 샘플링
- 두 번째 패치는 첫 번째 패치 위치를 기준으로 8개의 가능한 이웃 위치 중 무작위 선택
이 설명은 이 설계는 각 패치의 독립적인 특징 추출과 후반부의 제한된 융합을 통해, 패치 간의 상대적 위치 관계를 학습하면서도 개별 패치의 의미있는 표현을 학습할 수 있도록 합니다.
3-1. Avoiding “trivial” solutions

이 내용은 구현 세부사항(Implementation Details)을 다루는 부분으로, pretext task 설계 시 발생할 수 있는 문제점들과 그 해결 방법, 그리고 구체적인 구현 방법을 설명합니다.
- Pretext Task 설계 시 주의사항
- 네트워크가 " trivial shortcuts"(쉬운 지름길)을 택하지 않도록 설계
- 패치 간 경계 패턴이나 텍스처의 연속성 같은 저수준 단서 방지
- 패치 사이에 간격 추가 (패치 너비의 약 절반)
- 패치 위치를 최대 7픽셀까지 무작위로 지터링 (Figure 2)
- 색수차(Chromatic Aberration) 문제와 해결방안
- 렌즈가 파장에 따라 빛을 다르게 초점 맞추는 현상
- 녹색 채널이 다른 채널들에 비해 이미지 중심으로 수축
- 두 가지 전처리 방법 제안:
- 'projection': 녹색과 마젠타를 회색으로 이동
- 'color dropping': 3개의 색상 채널 중 2개를 무작위로 제거하고, 제거된 색상 채널을 가우시안 노이즈로 대체
더보기(Gaussian Noise)은 정규 분포(가우스 분포)와 동일한 확률 밀도 함수(pdf)를 갖는 신호 잡음의 일종
- 구현 세부사항
- 사용 도구: Caffe
- 데이터셋: ImageNet 2012 학습 세트 (1.3M 이미지, 라벨 미사용)
- 이미지 전처리:
- 150K-450K 픽셀 크기로 리사이징
- 96x96 해상도의 패치 샘플링
- 그리드 패턴으로 패치 샘플링 (최대 8개 페어링)
- 패치 간 48픽셀 간격, -7~7픽셀 지터링
- 학습 관련 문제와 해결방안
- SGD 적용 시 네트워크 예측이 8개 카테고리에 대해 균일한 예측으로 퇴화
- fc6와 fc7의 활성화가 0으로 붕괴
- 해결 방법:
- Batch normalization 적용 (scale과 shift 없이)
- 높은 모멘텀 값(.999) 사용으로 학습 가속화
이 설명은 pretext task가 의도한 의미론적 학습을 위한 기술적 문제와 해결책, 구현에 필요한 파라미터와 설정을 상세히 제시합니다.
4. Experiments
이 내용은 논문의 실험 섹션으로 논문에서 진행한 실험 설명을합니다
- 실험의 구성 네트워크 평가를 위한 세 가지 주요 실험 방향을 제시:
- 의미적 유사성 검증 (Semantic Similarity Validation)
- 최근접 이웃(nearest-neighbor) 매칭을 통해 의미적으로 유사한 패치들을 연관시키는 능력 검증
- 제한된 데이터에서의 전이학습 (Transfer Learning with Limited Data)
- VOC 2007 객체 탐지 태스크에서 "pre-training" 모델로 활용
- 제한된 훈련 데이터 상황에서의 성능 평가
- 시각적 데이터 마이닝 (Visual Data Mining)
- 레이블이 없는 이미지 컬렉션에서 객체 클래스 자동 발견 능력 평가
- Pretext Task 성능 분석 (Pretext Task Performance Analysis)
- 레이아웃 예측이라는 pretext task에서의 성능 분석
- 감독 신호(supervisory signal)에서 얼마나 더 학습할 수 있는지 평가
이 설명은 제안된 방법의 효과성을 다양한 각도에서 검증하기 위한 실험 프레임워크를 제시하고 있습니다. 특히, 실제 응용(객체 탐지)부터 비지도 학습(데이터 마이닝)까지 폭넓은 평가를 계획하고 있음을 보여줍니다.
4-1. Nearest Neighbors
이 학습된 네트워크가 어떤 패치들을 의미적으로 유사하다고 판단하는지 분석하는 실험 결과를 설명하는 부분입니다
- 실험 목적과 의미
- 네트워크가 의미적으로 유사한 패치들에 유사한 표현을 할당하는지 검증
- 어떤 패치들을 네트워크가 유사하다고 판단하는지 이해
- 실험 방법
- 96x96 크기의 무작위 패치 샘플링
- fc6 특징 사용 (Figure 3에서 fc7 이상 제거, 단일 스택만 사용)
- 정규화된 상관관계를 사용하여 최근접 이웃 탐색
- 비교 실험
- ImageNet으로 학습된 AlexNet의 fc7 특징 사용 (패치 업샘플링)
- 학습되지 않은(무작위 초기화) 네트워크의 fc6 특징 사용
- 실험 결과 (Figure 4)
- 제안된 방법의 특징이 의도한 의미적 정보를 잘 포착
- AlexNet과 비교하여 의미적 내용면에서 대등한 성능
- 일부 경우(예: 자동차 바퀴)에서 더 나은 자세 포착
- 흥미롭게도 학습되지 않은 ConvNet도 일부 경우에 준수한 성능 보임
제안된 방법이 의미적으로 유사한 패치들을 효과적으로 식별할 수 있음을 실험적으로 검증하고, 기존 방법(AlexNet)과의 비교를 통해 그 성능을 입증합니다.
4-2. Aside: Learnability of Chromatic Aberration

이 내용은 색수차(chromatic aberration) 문제가 네트워크 학습에 미치는 영향을 분석한 실험 결과를 설명합니다.
- 초기 실험
- 최근접 이웃 실험에서 발견된 현상
- 내용과 무관하게 이미지 내 동일한 절대 위치의 패치들이 매칭됨
- 유사한 색수차를 보이는 패치들이 매칭되는 문제 발견
- 검증 실험 설계
- ImageNet에서 샘플링된 패치들의 절대 좌표 (x, y)를 예측하는 네트워크 학습
- 전반적인 정확도는 높지 않았으나 일부 이미지에서 놀라운 성능 보임
- 실험 결과
- 상위 10% 이미지에 대한 성능:
- 평균 제곱근 오차(RMSE): 0.255
- 무작위 추측(이미지 중심 예측) RMSE: 0.371
- "projection" 기법 적용 후 상위 10% 이미지의 오차가 0.321로 증가 (Figure 5)
- 이는 색수차를 통한 "쉬운 해결책"을 효과적으로 방지함을 보여줌
- 상위 10% 이미지에 대한 성능:
이 설명은 색수차 현상이 네트워크 학습에 예상치 못한 영향을 미칠 수 있음을 실험을 통해 확인하고, 이를 해결하기 위해 제안된 "projection" 기법이 어떻게 효과적으로 작용하는지 구체적으로 입증합니다.
4-3. Object Detection
이 내용은 실험 결과 부분으로, 제안된 방법을 PASCAL VOC 객체 탐지 과제에 적용한 결과와 실험 변형을 설명합니다.
- 실험 설정
- R-CNN 파이프라인 사용
- 227x227 크기의 객체 제안 영역 처리
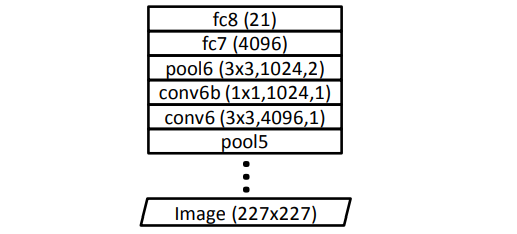
- 네트워크 아키텍처 수정 (Figure 6):
- 단일 스택만 사용
- 컨볼루션 레이어를 227x227 입력에 맞게 조정
- fc6를 conv6로 변환
- conv6b 레이어 추가 (1x1 커널, 4096→1024 채널)
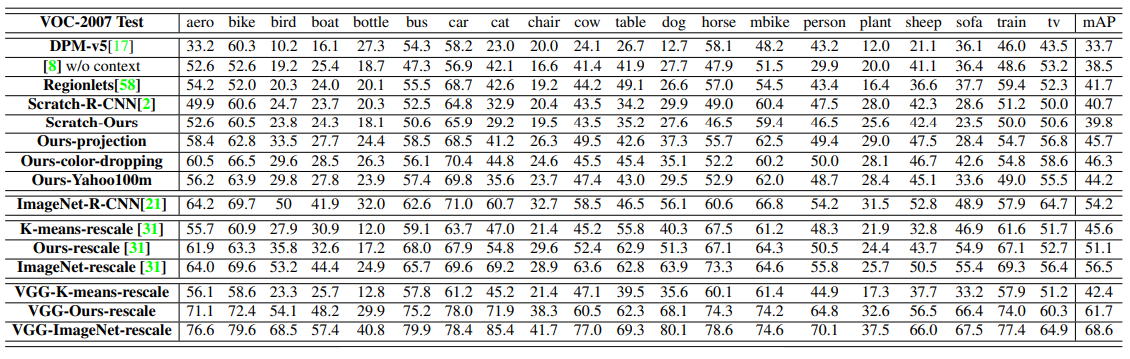
- 주요 실험 결과 (Table 1)
- 무작위 초기화 대비 6% MAP 향상
- PASCAL에서 처음부터 학습한 AlexNet 대비 5% 이상 향상
- ImageNet 라벨로 사전학습된 R-CNN보다 8% 낮은 성능
- Yahoo/Flickr 100M 데이터셋 실험:
- ImageNet보다 약간 낮은 성능
- 무작위 초기화 대비 상당한 성능 향상
- Batch Normalization 관련 실험
- 평균과 분산을 추정하여 batch normalization 레이어 제거
- 가중치 스케일링의 중요성 확인
- VGG 구조 실험
- 16-layer VGG 구조 적용
- Fast R-CNN으로 미세조정
- 학습 시간: Titan X GPU에서 약 8주
- AlexNet 스타일 모델보다 상당한 성능 향상
- K-means 초기화 베이스라인과 비교
이 설명은 제안된 비지도 학습 방법이 객체 탐지 같은 실제 비전 과제에서 효과적임을 입증합니다. 특히 라벨이 없는 데이터로 사전학습했음에도 성능 향상을 달성했으며, 더 복잡 네트워크 구조에서도 좋은 결과를 보여줍니
4-4. Geometry Estimation
이 내용은 제안된 표현 학습 방법이 객체 탐지뿐만 아니라 다른 비전 과제에도 유효한지를 평가한 결과를 설명합니다.
- 실험 동기
- 이전 실험(Section 4.3)에서 객체 인식에 대한 효과성 입증
- 객체 기반이 아닌 다른 과제에서의 유용성 검증 필요
- 실험 설정
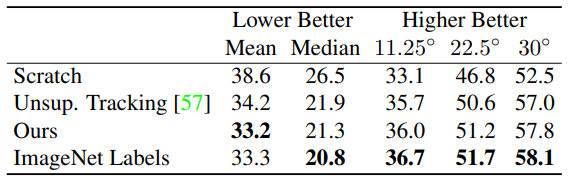
- NYUv2 데이터셋의 표면 법선 추정(surface normal estimation) 작업 수행
- Fouhey et al.의 방법론 사용
- Wang et al.의 fine-tuning 절차 따름
- color-dropping network 사용
- Section 4.3과 같은 방식으로 fully-connected 레이어 재구성
- 주요 결과
- ImageNet 라벨로 학습된 모델과 거의 동등한 성능 달성
- 가능한 설명:
- ImageNet 분류 과제는 기하학적 정보에 덜 주목
- 객체 식별 후에는 기하학적 특성이 크게 중요하지 않음
- 시각적 증거 (Figure 4)
- ImageNet AlexNet의 최근접 이웃 결과 분석
- 자동차 바퀴 예시: 객체는 동일하게 인식하지만 기하학적 정렬은 부정확
이 실험 결과는 제안된 비지도 학습 방법이 객체 탐지뿐만 아니라 기하학적 특성이 중요한 작업에서도 효과적임을 보여주며, 특히 레이블이 있는 ImageNet 모델과 비슷한 성능을 달성했다는 점이 인상적입니다.
4-5. Visual Data Mining


이 내용은 실험 결과 중 시각적 데이터 마이닝(Visual Data Mining)과 비지도 객체 발견(Unsupervised Object Discovery) 부분을 설명합니다.
- 시각적 데이터 마이닝의 목적
- 대규모 이미지 컬렉션에서 동일한 의미적 객체를 포함하는 이미지 조각 발견
- 응용: 데이터셋 시각화, 콘텐츠 기반 검색, 시각 데이터와 비구조화 정보(예: GPS 좌표) 연결
- 제안하는 접근 방법
- 동일 객체에서 비중첩 패치 샘플링
- 4개의 인접 패치로 구성된 constellation 사용
- 공간 배치를 무시하고 상위 100개 이미지 매칭
- 기하학적 검증을 통한 필터링
- 구현 세부사항
- 기하학적 검증 방법:
- 패치 중심에 최적의 정사각형 맞춤
- 정규화된 제곱 오차 계산
- 오차가 1 미만일 때 검증 통과
- 색상 드롭핑(Color-dropping ) 버전의 네트워크 사용
- 데이터 증강 전처리 단계 미사용
- 기하학적 검증 방법:
- 실험 결과
- Pascal VOC 2011 데이터셋 적용 결과 (Figure 7) :
- 모니터, 새, 몸통, 음식 접시 등 새로운 객체 발견
- 변형이 많은 객체(새, 몸통)도 발견
- 이전 연구와 비교하여 더 다양한 객체 발견
- 파리 Street View 이미지 실험 (Figure 8):
- 장면 레이아웃과 건축 요소 포착
- 파리의 Street View 이미지 15,000장 적용
- Pascal VOC 2011 데이터셋 적용 결과 (Figure 7) :
- 장단점 분석
- 장점:
- 더 다양한 객체 발견
- 그레이팅(gratings) 문제 해결
- 다양한 시점의 객체 발견
- 단점:
- 일부 순도 손실
- 객체 마스크 자동 결정 불가
- 장점:
이 설명은 제안된 방법이 시각적 데이터 마이닝 작업에서 효과적으로 작동함을 입증하며, 특히 다양한 객체와 장면 구조를 효과적으로 발견할 수 있음을 실험을 통해 증명합니다.
4-5-1. Quantitative Results
이 내용은 정성적 평가(Qualitative Evaluation) 부분으로, Pascal VOC 2007 데이터셋에 대한 실험 결과를 다룹니다.
- 실험 설정
- 데이터셋: Pascal VOC 2007의 부분집합
- 버스, 식탁, 오토바이, 말, 소파, 기차 중 하나 이상 포함
- 평가 방법: purity coverage curve 사용
- 평가 데이터: 10개 이미지로 구성된 1000개 세트
- 데이터셋: Pascal VOC 2007의 부분집합
- 평가 방법
- 순도(Purity) 계산:
- 클러스터 내 동일 카테고리 포함 이미지 비율
- 커버리지(Coverage) 계산:
- 데이터셋 내 최소 하나의 세트에 포함된 이미지 비율
- 순위별 정렬 및 곡선 생성
- 순도(Purity) 계산:
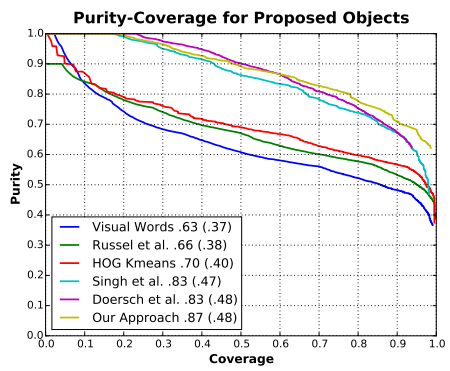
- 실험 결과 (Figure 9)
- 장점: 커버리지 측면에서 상당한 향상
- 학습된 특징의 향상된 불변성(invariance) 입증
- 단점: Context as supervisory signal: Discovering objects with predictable context. 와 비교해 높은 순도의 클러스터 일부 손실
- 더 단순한 검증 절차 사용으로 인한 예상된 결과
- 장점: 커버리지 측면에서 상당한 향상
- 구현 세부사항
- 초기 클러스터링:
- 16,384개 클러스터 초기화
- 패치 샘플링
- 최근접 이웃 마이닝
- 기하학적 검증 순위화
- 클러스터 선택 절차:
- 각 클러스터당 상위 10개 기하학적 검증된 이웃 선택
- 커버리지 점수에 기여하는 최상위 클러스터 반복 선택
- 모든 이미지가 최소 2회, 3회 이상 포함되도록 확장
- 초기 클러스터링:
이 설명은 제안된 방법의 성능을 정량적으로 평가하기 위한 실험 설계와 그 결과를 보여줍니다. 특히 커버리지 측면에서의 개선을 보여주지만, 순도 측면에서는 trade-off가 있음을 보여줍니다.
4-6. Accuracy on the Relative Prediction Task Task
이 내용은 네트워크의 성능을 평가하기 위해 세 가지 주요 실험을 수행했습니다.
- 기본 성능 검증
- 의미적으로 유사한 패치들의 연관성을 학습했는지 확인
- 단순한 최근접 이웃(nearest-neighbor) 매칭을 통한 검증
- 응용 분야 1: 제한된 데이터셋에서의 사전 학습
- VOC 2007 객체 탐지 작업에 적용
- 제한된 훈련 데이터에서의 성능 평가
- 응용 분야 2: 시각적 데이터 마이닝
- 레이블이 없는 이미지 컬렉션에서 시작
- 객체 클래스의 자동 발견 능력 평가
- Pretext Task 분석
- 레이아웃 예측이라는 pretext task에서의 성능 분석
- 이 감독 신호로부터 얼마나 더 학습할 수 있는지 평가
이 설명은 제안된 방법의 효과성을 다양한 각도에서 검증하려는 체계적인 실험 설계를 보여줍니다.
Reference
논문 출저: Unsupervised Visual Representation Learning by Context Prediction



