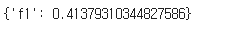# ENTAILMENT: 첫 번째 문장이 두 번째 문장을 내포하거나 함축한 경우
# NEUTRAL: 두 문장의 관계가 특별히 긍정적이거나 부정적이지 않을 때(모순 관계가 없을 때)
# CONTRADICTION: 명백한 모순 관계가 있을 때
classifier(f'나는 게임을 너무 좋아해 {tokenizer.sep_token} 나는 게임이 너무 싫어')
classifier(f'여러 남성들이 축구를 즐기고 있어요 {tokenizer.sep_token} 어떤 남자들은 공을 차고 있어요')
import torch
from transformers import PreTrainedTokenizerFast
from transformers import BartForConditionalGeneration
# PreTrainedTokenizerFast: 허깅페이스에서 개발한 Rust 기반의 고성능 토크나이저
tokenizer = PreTrainedTokenizerFast.from_pretrained('digit82/kobart-summarization')
tokenizer
model = BartForConditionalGeneration.from_pretrained('digit82/kobart-summarization')
text = """
기후 관련 신기록들이 나오고 있다. 지난 6월 5일 '세계기상기구'(WMO)는 향후 5년간 산업혁명 전 대비 지구표면 온도가 1.1℃에서 1.9℃까지 상승할 수 있다고 발표했다. 기후위기의 마지노선인 1.5℃ 상승이 앞으로 5년간 계속될 확률도 47%라고 한다. 1.5℃ 상승제한을 결정했던 2015년 유엔 파리기후협정 당시만 해도 2030년까지 1.5℃ 오를 가능성은 0%였다. 10년도 안 되어 사실상 기후 관련 국제사회의 결정이 무너지고 있다.
지난 6월 28일 발생해 시속 270km의 강풍을 동반, 최고등급인 5등급으로 발달한 허리케인 '베릴'(Beryl)이 중남미 카리브해의 나라들을 파괴했다. 7월 3일 영국 BBC방송은 베릴에 대해 지난 100년간의 허리케인 기록을 깼고, 현재 진행되는 기후변화의 위험성이 집중 조명된 사례로 보도했다. 지금까지 허리케인은 해수면 온도가 높아진 8월 말부터 발생했는데, 6월에 발생한 허리케인 베릴은 기후위기가 만든 최초 기록이라는 것이다.
"""
ynat: 유튜브 비디오 댓글에서 자연스럽게 발생하는 대화 데이터를 이용한 태스크, 주어진 문장에 대해 답변하는 작업
sts: 두 텍스트의 의미적 유사성을 평가하는 태스크
nil: 전제와 가설이라는 두 문장 간의 논리적 관계를 판별하는 태스크(참, 거짓, 중립)
ner: 문장에서 인명, 지명, 기관면 등 특정 개체명을 식별하고 분류하는 태스크
re: 문장 또는 텍스트에서 개체들 간의 관계를 추출하는 태스크
예) "스티브잡스는 애플의 공동 창립자이다" -> 스티브잡스와 애플을 뽑아내고 그 관계를 알려줌
dp: 문장 내 단어들 간의 문법적 관계를 파악하는 태스크. 각 단어가 어떻게 다른 단어들과 연결되어 있는지(종속성)를 구조적으로 분석
mrc: 주어진 텍스트와 질문에 대해 답을 추출하거나 생성하는 태스크. 모델이 텍스트를 읽고 이해햐여 질문에 답할 수 있도록 함
wos: Web of Science: 데이터베이스에서 추출한 데이터를 활용하는 태스크. 특정 태스크보다는 데이터의 출처를 나타냄
import datasets
from datasets import load_dataset, ClassLabel,load_metric
import random
import pandas as pd
from IPython.display import display, HTML
from transformers import AutoTokenizer, pipeline, AutoModelForSequenceClassification, TrainingArguments, Trainer
import numpy as np
import tensorflow as tf
def preprocess_function(examples):
return tokenizer(
examples['title'],
truncation=True, # 최대 길이를 초과할 경우 초과된 부분을 잘라냄
return_token_type_ids=False,
)
preprocess_function(datasets['train'][:5])
num_labels = 7
# AutoModelForSequenceClassification
# 시퀀스 분류 작업(예: 감정분석, 텍스트 분류)
# 다양한 모델(BERT, RoBERTa 등) 지원
model = AutoModelForSequenceClassification.from_pretrained(model_checkpoint,num_labels=num_labels)
metric_name = 'f1'
args = TrainingArguments(
'test-tc',
# 평가전략: 에폭이 끝날 때마다 평가를 수행
evaluation_strategy='epoch',
# 모델 체크포인트를 저장. 매 에포크마다 저장
save_strategy='epoch',
learning_rate = 2e-5,
per_device_train_batch_size=batch_size,
per_device_eval_batch_size = batch_size,
num_train_epochs = 5,
# 가중치 감소의 설정
weight_decay=0.01,
# 학습이 끝난 후 가장 좋은 성능을 보인 모델을 불러올지 결정
load_best_model_at_end = True,
# 최적의 모델을 결정할 때 사용할 메트릭을 지정
metric_for_best_model = metric_name
)
trainer = Trainer(
model,
args,
train_dataset=encoded_datasets['train'],
eval_dataset=encoded_datasets['validation'],
tokenizer=tokenizer,
compute_metrics=compute_metrics
)
trainer.train()
trainer.evaluate()
classifier = pipeline(
'text-classification',
model = './test-tc/checkpoint-1428',
return_all_scores=True
)
'''
0 (IT과학)
1 (경제)
2 (사회)
3 (생활문화)
4 (세계)
5 (스포치)
6 (정치)
'''
classifier('평생 처음 주민들의 충격 증언... 대한민국 곳곳 이상직후')