
1. 문장 임베딩
- 2017년 이전의 임베딩 기법들은 대부분 단어 수준 모델이였음(Word2Vec, FastText, GloVe)
- 단어 수준 임베딩 기법은 자연어의 특성인 모호성, 동음이의어를 구분하기 어렵다는 한계가 있음
- 2017년 이후에는 ELMo(Embeddings from Language Models) 와 같은 모델이 발표되고 트랜스포머와 같은 언어 모델에서 문장 수준의 언어 모델링을 고려하면서 한계점들이 해결됨
2. Seq2Seq 배경
- Seq2Seq 모델 등장하기 전에 DNN( Deep Neural Network) 모델은 사물인식, 음성인식 등에서 꾸준히 성과를 냈음( ex, CNN, RNN, LSTM, GRU ....)
- 모델 입/출력의 크기가 고정된다는 한계점이 존재 했기 때문에 자연어 처리와 같은 가변적인 길이의 입/출력 처리하는 문제들을 제대로 해결할 수 없었음
- RNN은 Seq2Seq가 등장하기 전에 입/출력을 시퀀스 단위로 처리할 수 있는 모델이었음
2-1. Seq2Seq( Sequense to Sequence)란?
- 2014년 구글에서 논문 으로 제안한 모델
- LSTM(Long Short-Term Memory)또는 GRU(Gated Recurrent Unit) 기분의 구조를 가지고 고정된 길이의 단어 시퀀스를 입력으로 받아, 입력 시퀀스에 알맞은 길이의 시퀀스를 출력해주는 언어 모델
- 2개의 LSTM을 각각 Encoder와 Decoder로 사용해 가변적인 길이의 입/출력을 처리하고자 했음
- 기계번역 작업에서 큰성능을 항상 가져왔고, 특히 긴 문장을 처리하는데 강점이 있음
2-2. 인코더
- 입력 문장을 컨텍스트 벡터에 인코딩(압축)하는 역할을 함
- 인코더의 LSTM은 입력 문장을 단어 순서대로 처리하여 고정된 크기의 컨텍스트 벡터를 반환
- 컨텍스트 벡터는 인코더의 마지막 스텝에서 출력된 hidden state와 같음
- 컨텍스트 벡터는 입력 문장의 정보를 함축하는 벡터이므로, 해당 벡터를 입력 문장에 대한 문장 수준의 벡터로 활용할 수 있음
class Encoder(nn.Module):
def __init__(self, input_size, hidden_size):
super(Encoder, self).__init__()
self.input_size = input_size
self.hidden_size = hidden_size
self.embedding = nn.Embedding(input_size, hidden_size)
self.gru = nn.GRU(input_size, hidden_size)
def forward(self, input):
embedded = self.embedding(input).view(1, 1, -1)
output, hidden = self.gru(embedded)
return output, hidden
class Decoder(nn.Module):
def __init__(self, hidden_size, output_size):
super(Decoder, self).__init__()
self.hidden_size = hideen_size
self.output_size = output_size
self.embedding = nn.Embedding(output_size, hidden_size)
self.gru = nn.GRU(embedding, hidden_size)
self.out = nn.Linear(hidden_size, output_size)
def forward(self, input, hidden):
output = self.embedding(input).view(1, 1, -1)
output = F.relu(output)
output, hidden = self.gru(output, hidden)
output = self.out(output[0])
return output, hidden
2-3. 디코더
- 입력 문장의 정보가 압축된 컨텍스트 벡터를 사용하여 출력 문장을 디코딩 하는 역할
- 컨텐스트 벡터와 문장의 시작을 뜻하는 토큰을 입력으로 받아서 문장의 끝을 뜻하는 토큰이 나올 때까지 문장을 생성
- LSTM의 첫 셀에서는 토큰과 컨텍스트 벡터를 입력 받아서 그 다음에 등장할 확률이 가장 높은 단어를 예측하고, 다음 스텝에서 예측한 단어를 입력으로 받아서, 그 다음에 등장할 확률이 가장 높은 단어를 예측함
2-4. 학습과정과 한계점
- 모델 학습 과정에서는 이전 셀에서 예측한 단어를 다음 셀의 입력으로 넣어주는 대신 실제 정답 단어를 다음 셀의 입력으로 넣기도 함(교사 강요)
- 위 방법으로 학습하지 않으면 이전 셀에서의 오류가 다음 셀로 계속 전파될 것이기 때문에 학습이 제대로 되지 않고 오래 걸릴 수 있음
- 가변적인 길이의 입/출력을 처리하는데 효과적인 모델 구조이며, 실제로 기계 번역 작업에서 성능 향상을 거뒀으나 여전히 한계를 가짐
- 인코더가 출력하는 벡터 사이즈가 고정되어 있기 때문에 입력으로 들어오는 단어의 수가 매우 많아지면 성능이 떨어짐
- RNN 구조의 모델에서는 hidden state를 통해 이전 셀의 정보를 다음 셀로 계속 전달하게 되는데 문장의 길이가 길어지면 초기 셀에서 전달했던 정보들이 점차 흐려짐(LSTM, GRU 같은 모델들이 제안되긴 했으나 여전히 이전 정보를 계속 압축하는데 한계는 있음)
import os
import re
import shutil
import zipfile
import requests
import numpy as np
import pandas as pd
import unicodedata
import urllib3
import torch
import torch.nn as nn
import torch.optim as optim
import numpy as np
import torch.nn.functional as F
from tensorflow.keras.preprocessing.text import Tokenizer
from tensorflow.keras.preprocessing.sequence import pad_sequences
from torch.utils.data import DataLoader, TensorDatasetheaders = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36'
}
def download_zip(url, output_path):
response = requests.get(url, headers=headers, stream=True)
if response.status_code == 200:
with open(output_path, 'wb') as f:
for chunk in response.iter_content(chunk_size=8192):
f.write(chunk)
print(f"ZIP file downloaded to {output_path}")
else:
print(f"Failed to download. HTTP Response Code: {response.status_code}")
url = "http://www.manythings.org/anki/fra-eng.zip"
output_path = "fra-eng.zip"
download_zip(url, output_path)
path = os.getcwd()
zipfilename = os.path.join(path, output_path)
with zipfile.ZipFile(zipfilename, 'r') as zip_ref:
zip_ref.extractall(path)
num_samples = 33000def to_ascii(s):
# 프랑스어 악센트(accent) 삭제
# 예시 : 'déjà diné' -> deja dine
return ''.join(c for c in unicodedata.normalize('NFD', s)
if unicodedata.category(c) != 'Mn')
def preprocess_sentence(sent):
# 악센트 제거 함수 호출
sent = to_ascii(sent.lower())
# 단어와 구두점 사이에 공백 추가.
# ex) "I am a student." => "I am a student ."
sent = re.sub(r"([?.!,¿])", r" \1", sent)
# (a-z, A-Z, ".", "?", "!", ",") 이들을 제외하고는 전부 공백으로 변환.
sent = re.sub(r"[^a-zA-Z!.?]+", r" ", sent)
# 다수 개의 공백을 하나의 공백으로 치환
sent = re.sub(r"\s+", " ", sent)
return sent# 전처리 테스트
en_sent = u"Have you had dinner?"
fr_sent = u"Avez-vous déjà diné?"
print('전처리 전 영어 문장 :', en_sent)
print('전처리 후 영어 문장 :',preprocess_sentence(en_sent))
print('전처리 전 프랑스어 문장 :', fr_sent)
print('전처리 후 프랑스어 문장 :', preprocess_sentence(fr_sent))
def load_preprocessed_data():
encoder_input, decoder_input, decoder_target = [], [], []
with open("fra.txt", "r") as lines:
for i, line in enumerate(lines):
# source 데이터와 target 데이터 분리
src_line, tar_line, _ = line.strip().split('\t')
# source 데이터 전처리
src_line = [w for w in preprocess_sentence(src_line).split()]
# target 데이터 전처리
tar_line = preprocess_sentence(tar_line)
tar_line_in = [w for w in ("<sos> " + tar_line).split()]
tar_line_out = [w for w in (tar_line + " <eos>").split()]
encoder_input.append(src_line)
decoder_input.append(tar_line_in)
decoder_target.append(tar_line_out)
if i == num_samples - 1:
break
return encoder_input, decoder_input, decoder_targetsents_en_in, sents_fra_in, sents_fra_out = load_preprocessed_data()
print('인코더의 입력 :',sents_en_in[:5])
print('디코더의 입력 :',sents_fra_in[:5])
print('디코더의 레이블 :',sents_fra_out[:5])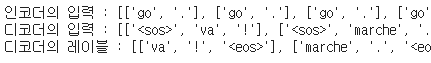
tokenizer_en = Tokenizer(filters="", lower=False)
tokenizer_en.fit_on_texts(sents_en_in)
encoder_input = tokenizer_en.texts_to_sequences(sents_en_in)
encoder_input = pad_sequences(encoder_input, padding="post")
tokenizer_fra = Tokenizer(filters="", lower=False)
tokenizer_fra.fit_on_texts(sents_fra_in)
tokenizer_fra.fit_on_texts(sents_fra_out)
decoder_input = tokenizer_fra.texts_to_sequences(sents_fra_in)
decoder_input = pad_sequences(decoder_input, padding="post")
decoder_target = tokenizer_fra.texts_to_sequences(sents_fra_out)
decoder_target = pad_sequences(decoder_target, padding="post")print('인코더의 입력의 크기(shape) :',encoder_input.shape)
print('디코더의 입력의 크기(shape) :',decoder_input.shape)
print('디코더의 레이블의 크기(shape) :',decoder_target.shape)
src_vocab_size = len(tokenizer_en.word_index) + 1
tar_vocab_size = len(tokenizer_fra.word_index) + 1
print("영어 단어 집합의 크기 : {:d}, 프랑스어 단어 집합의 크기 : {:d}".format(src_vocab_size, tar_vocab_size))
src_to_index = tokenizer_en.word_index
index_to_src = tokenizer_en.index_word
tar_to_index = tokenizer_fra.word_index
index_to_tar = tokenizer_fra.index_wordindices = np.arange(encoder_input.shape[0])
np.random.shuffle(indices)
print('랜덤 시퀀스 :',indices)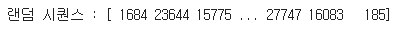
encoder_input = encoder_input[indices]
decoder_input = decoder_input[indices]
decoder_target = decoder_target[indices]encoder_input[30997]
decoder_target[30997]
n_of_val = int(33000*0.1)
print('검증 데이터의 개수 :',n_of_val)
encoder_input_train = encoder_input[:-n_of_val]
decoder_input_train = decoder_input[:-n_of_val]
decoder_target_train = decoder_target[:-n_of_val]
encoder_input_test = encoder_input[-n_of_val:]
decoder_input_test = decoder_input[-n_of_val:]
decoder_target_test = decoder_target[-n_of_val:]print('훈련 source 데이터의 크기 :',encoder_input_train.shape)
print('훈련 target 데이터의 크기 :',decoder_input_train.shape)
print('훈련 target 레이블의 크기 :',decoder_target_train.shape)
print('테스트 source 데이터의 크기 :',encoder_input_test.shape)
print('테스트 target 데이터의 크기 :',decoder_input_test.shape)
print('테스트 target 레이블의 크기 :',decoder_target_test.shape)
embedding_dim = 64
hidden_units = 64class Encoder(nn.Module):
def __init__(self, input_size, hidden_size):
super(Encoder, self).__init__()
self.input_size = input_size
self.hidden_size = hidden_size
self.embedding = nn.Embedding(input_size, hidden_size)
self.gru = nn.GRU(hidden_size, hidden_size, batch_first=True)
def forward(self, input):
embedded = self.embedding(input)
output, hidden = self.gru(embedded)
return output, hidden
class Decoder(nn.Module):
def __init__(self, hidden_size, output_size):
super(Decoder, self).__init__()
self.hidden_size = hidden_size
self.output_size = output_size
self.embedding = nn.Embedding(output_size, hidden_size)
self.gru = nn.GRU(hidden_size, hidden_size, batch_first=True)
self.out = nn.Linear(hidden_size, output_size)
def forward(self, input, hidden):
embedded = self.embedding(input)
embedded = F.relu(embedded)
output, hidden = self.gru(embedded, hidden)
output = self.out(output)
return output, hiddenclass Seq2Seq(nn.Module):
def __init__(self, encoder, decoder):
super(Seq2Seq, self).__init__()
self.encoder = encoder
self.decoder = decoder
def forward(self, src, trg):
encoder_outputs, hidden = self.encoder(src)
decoder_outputs, _ = self.decoder(trg, hidden)
return decoder_outputsencoder = Encoder(src_vocab_size, hidden_units)
decoder = Decoder(hidden_units, tar_vocab_size)
model = Seq2Seq(encoder, decoder)loss_func = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters())encoder_input_train_tensor = torch.tensor(encoder_input_train, dtype=torch.long)
decoder_input_train_tensor = torch.tensor(decoder_input_train, dtype=torch.long)
decoder_target_train_tensor = torch.tensor(decoder_target_train, dtype=torch.long)
encoder_input_test_tensor = torch.tensor(encoder_input_test, dtype=torch.long)
decoder_input_test_tensor = torch.tensor(decoder_input_test, dtype=torch.long)
decoder_target_test_tensor = torch.tensor(decoder_target_test, dtype=torch.long)train_dataset = TensorDataset(encoder_input_train_tensor, decoder_input_train_tensor, decoder_target_train_tensor)
test_dataset = TensorDataset(encoder_input_test_tensor, decoder_input_test_tensor, decoder_target_test_tensor)
batch_size = 64
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
test_loader = DataLoader(test_dataset, batch_size=batch_size, shuffle=False)def train_model(model, optimizer, loss_func, train_loader, epochs):
model.train()
for epoch in range(epochs):
total_loss = 0
for encoder_input_train_tensor, decoder_input_train_tensor, decoder_target_train_tensor in train_loader:
optimizer.zero_grad()
outputs = model(encoder_input_train_tensor, decoder_input_train_tensor)
loss = loss_func(outputs.view(-1, outputs.shape[-1]), decoder_target_train_tensor.view(-1))
loss.backward()
optimizer.step()
total_loss += loss.item()
print(f'Epoch [{epoch+1}/{epochs}], Loss: {total_loss/len(train_loader):.4f}')
# 학습 시작
train_model(model, optimizer, loss_func, train_loader, epochs=10)
# 디코드 시퀀스 함수
def decode_sequence(input_seq):
input_tensor = torch.tensor(input_seq, dtype=torch.long)
with torch.no_grad():
encoder_output, hidden = model.encoder(input_tensor)
target_seq = torch.tensor([[tar_to_index['<sos>']]], dtype=torch.long)
decoded_sentence = ''
stop_condition = False
while not stop_condition:
with torch.no_grad():
output, hidden = model.decoder(target_seq, hidden)
sampled_token_index = output.argmax(2).item()
sampled_char = index_to_tar[sampled_token_index]
if sampled_char != '<eos>':
decoded_sentence += ' ' + sampled_char
if sampled_char == '<eos>' or len(decoded_sentence.split()) > 100:
stop_condition = True
target_seq = torch.tensor([[sampled_token_index]], dtype=torch.long)
return decoded_sentence
# 원문의 정수 시퀀스를 텍스트 시퀀스로 변환
def seq_to_src(input_seq):
sentence = ''
for encoded_word in input_seq:
if encoded_word != 0:
sentence += index_to_src.get(encoded_word, '') + ' '
return sentence.strip()
# 번역문의 정수 시퀀스를 텍스트 시퀀스로 변환
def seq_to_tar(input_seq):
sentence = ''
for encoded_word in input_seq:
if encoded_word != 0 and encoded_word != tar_to_index['<sos>'] and encoded_word != tar_to_index['<eos>']:
sentence += index_to_tar.get(encoded_word, '') + ' '
return sentence.strip()
# 테스트
for seq_index in [0, 1]:
input_seq = encoder_input_train[seq_index: seq_index + 1]
decoded_sentence = decode_sequence(input_seq)
print("입력문장 :", seq_to_src(encoder_input_train[seq_index]))
print("정답문장 :", seq_to_tar(decoder_input_train[seq_index]))
print("번역문장 :", decoded_sentence.strip())
print("-" * 50)
3. Attention Mechanism
- Seq2Seq 모델의 한계를 해결하기 위해 2014년도에 제안한 논문에서 발표
- 어텐션이라는 단어가 쓰이지 않았지만 어텐션 개념을 제공한 연구논문
- 어텐션 단어를 사용한 모델에 해당 논문
- 입력 시퀀스가 길어지면 출력 시퀀스의 정확도가 떨어지는 것을 보정해주기 위해 등장한 기법
- 어텐션의 아이디어는 디코더에서 출력 단어를 예측하는 매 시점(time step)마다 인코더에서의 전체 입력 문장을 다시 한 번 참고하는 것
- 단, 전체 입력 문장을 전부 다 동일한 비율로 참고하는 것이 아니라 해당 시점에서 예측해야 할 단어와 연관이 있는 입력 단어 부분을 좀 더 집중해서 보게 함
3-1. 어텐션 함수
- 어텐션 함수는 주어진 쿼리에 대해서 모든 키와의 유사도를 각각 계산
- 계산된 유사도를 키와 맵핑되어 있는 각각의 값에 반영한 뒤 유사도가 반영된 값을 모두 더해서 반환(어텐션 값)
- Q = Query : t 시점의 디코더 셀에서의 은닉 상태
- K = Keys : 모든 시점의 인코더 셀의 은닉 상태들
- V = Values : 모든 시점의 인코더 셀의 값
3-2. 어텐션의 작동 원리
- 시점의 예측하고자 하는 단어를 위해 입력 단어들의 정보를 다시 참고
- 어텐션 스코어를 구하는데 사용하는 수식은 다양하게 있으나 가장 간단한 dot product를 사용하느 것이 일반적
- 단어들의 정보를 참고하여 나온 확률 중 가장 큰 값을 예측하고자 하는 단어를 위해 사용함
4. ELMO(Embeddings from Language Model)
- 2018년에 논문에서 제안된 새로운 원드 임베딩 방법론
- ELMO의 가장 큰 특징은 사전 훈련된 언어 모델(Pre-Trained Language Model)을 사용한다는 것
- 기존 워드 임베딩은 주변 문맥 정보를 활용하여 단어를 벡터로 표현하는 방법을 사용(같은 표기 단어를 문맥에 따라 다르게 임베딩 할 수 없는 한계가 있었음)
- biLM이라는 구조를 사용(양방향의 언어 모델링을 통해 문맥적인표현을 반영하여 해당 입력 문장의 확률을 예측) 8 대량의 자연어 코퍼스를 미리 학습하여 코피스 안에 포함된 일반화된 언 특성들을 모델의 피라미터 안에 함축하여 사용하는 방법
4-1. 허깅페이스(Hugging Face)
- 인공지능 자연어 처리 기술을 중심으로 한 오픈소스 커뮤니티와 소프트웨어 플랫폼을 제공하는 사이트(회사)
- 특히 트랜스포머 모델들을 쉽게 사용할 수 있도록 하는 라이브러리(Transformers)로 유명
- 플랫폼과 라이브러리 등은 개발자와 AI 기업들에게 쉽게 학습시키고 배포할 수 있도록 도움
import json
import requestsAPI_TOKEN ='Your-API'
headers = {"Authorization": f"Bearer {API_TOKEN}"}
API_URL = "https://api-inference.huggingface.co/models/deepset/roberta-base-squad2"def query(data):
data = json.dumps(data)
response= requests.request("POST", API_URL, headers=headers, data=data)
return json.loads(response.content.decode("utf-8"))data = query(
{
"inputs": {
"question": "너의 이름이 뭐니?",
"context": "나는 서울에 살고 있고 내 이름은 김사과야"
}
}
)print(data)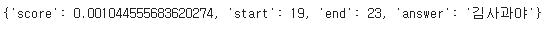
data = query(
{
"inputs": {
"question": "What's your name?",
"context": "I live in Seoul and my name is Kim Sagwa."
}
}
)print(data)
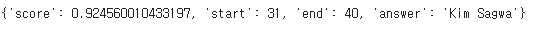
5. 트랜스포머(Transformer)
- 2017년 구글이 발표한 논문 "Attention is all you need" 에서 발표된 모델
- seq2seq의 구조인 인코더-디코더를 따르면서도 어텐션(Attention)만으로 구현된 모델
- RNN을 사용하지 않고 인코더-디코더 구조를 설계하였음에도 번역 성능에서도 RNN보다 월등히 성능을 보여주었으며 2017년 이후 지금까지도 다양한 분야에서 사용되는 범용적인 모델
5-1. 트랜스포머의 특징
- RNN을 사용하지 않지만 seq2seq 모델의 구조처럼 인코더에서 입력 시퀀스를 입력받고, 디코더에서 출력 시퀀스를 출력하는 인코더-디코더 형식을 사용함
- seq2seq 모델 구조에서는 인코더와 디코더를 각각 하나의 RNN 모델처럼 사용했다면, 트랜스포머에서는 인코더와 디코더 단위를 N개를 확장하는 구조를 사용(논문에서는 6개씩 사용)
5-2. 포지셔널 인코딩
- 트랜스포머는 단어의 위치 정보를 얻기 위해 각 단어의 임베딩 벡터에 위치 정보들을 더하여 모델의 입력으로 사용
- 위치 정보를 가진 값을 만들기 위해 sin, cos 함수를 사용(pos, i) 형태로 임베딩 벡터의 위치를 나타냄(i는 임베딩 벡터 내의 차원의 인덱스를 의미)
- 임베딩 벡터 내의 차원의 인덱스가 짝수인 경우에는 sin 함수의 값을 사용하고, 홀수인 경우에는 cos 함수의 값을 사용
- 각 임베딩 벡터에 포지셔널 인코딩의 값을 더하면 같은 단어라고 하더라도 문장 내의 위치에 따라 트랜스포머의 입력으로 들어가는 임베딩 벡터의 값이 달라짐
5-3. 트랜스포머 셀프 어텐션
- 어텐션을 스스로에게 수행한다는 의미
- 하나의 문장 내에서 단어 간의 관계를 파악하기 위해 사용하는 어텐션 메커니즘 (seq2seq와 동일)
5-4. 멀티해드 어텐션
- 어텐션에서는 d_model의 차원을 가진 단어 벡터를 num_heads로 나눈 차원으로 어텐션을 수행
- 트랜스포머 연구진은 한 번의 어텐션을 하는 것보다 여러번의 어텐션을 병렬로 사용하는 것이 더 효과적이라고 판단
- 병렬 어텐션을 모두 수행하면 모든 어텐션 헤드를 연결하며, 모두 연결된 어텐션 헤드 행렬 크기가(seq_len,d_model)이 됨
5-5. Position-wise FFNN(Feed Forward Neural Network)
- 일반적인 deep neuralnetwork의 feedforward 신경망
- 각각의 학습 노드가 서로 완전하게 연결된 Fully-connected NN이라고 해석할 수 있음
5-6. 멀티해드 어텐션
- 입력과 출력은 FFNN을 지나기 때문에 동일한 차원을 가지므로 덧셈이 가능
- 잔자 연결을 거친 결과에 layer nomalization 과정을 거침
- 수식으로 구현된 인코더는 총 num_layers만큼을 순차적으로 처리한 후에 마지막층의 인코더의 출력을 디코더로 전달하면서 디코더 연산이 시작
5-7. 디코더(Decoder)
- 디코더도 인코더와 동일하게 임베딩 층과 포지셔널 인코딩을 거친 후에 문장 행렬이 입력
- 학습시 교사강요 기법을 사용하여 학습되므로 학습 과정에서는 디코더는 정답 문장에 해당하는 문장 행렬을 한번에 입력
- Look-ahead mask 기법을 사용하여 현 시점의 정답이 아니라 이후에 나올 정답 단어들까지 참조하지 않도록 함
6. BERT(Bidirectional Encoder Representations from Transformers)
- 2018년도 Google의 논문에서 처음 제안된 모델로 Transformer의 인코더 기반의 언어 모델
- 버트는 unlabeled data로 부터 pre-train을 진행한 후, 특정 downstream task에 fine-tuning를 하는 모델
- downstream task: 주어진 문제나 작업에 특정하게 맞추어진 task를 의미
- fine-tuning: 사전 학습된 모델을 새로운 작업 또는 데이터셋에 맞게 조정하는 과정
- deep bidirectional을 더욱 강조하여 기존의 모델들과의 차별성을 강조
- 하나의 output layer만을 pre-trained BERT 모델에 추가하여 NLP의 다양한 주요 task(11개)에서 SOTA를달성
6-1. BERT 모델 구조
- Pre-training part와 Fine-tuning part로 나눠짐
- Pre-training 에서는 다양한 pre-training tasks의 unlabeled data를 활용해 파라미터를 조정하고 이를 바탕으로 학습된 모델은 Fine-tuning에서 downstream task의 labeled data를 이용함
- 양방향 Transformer encoder를 여러 층 쌓은 것
6-2. BERT의 사전 학습
- MLM (Masked Language Modeling)
- input tokens의 일정 비율을 마스킹하고 마스킹 된 토큰을 예측하는 과정
- pre-training과 fine-tuning 사이의 mismatch가 발생할 수 있음(마스크 토큰이 fine-tuning 과정에서는 나타나지 않게 추가적인 처리가 필요)
- NSP (Next Sentence Prediction)
- downstream task 두 문장 사이의 연속성을 확인하는 것이 핵심
- 문장 A와 B를 선택할 때 50%는 실제 A의 다음 문장인 B를 고르고 나머지 50%는 랜덤 문장 B에서 고르게 함
7. GPT(Generative pre-trained transformer)
- GPT 모델은 2018년 6월에 OpenAI가 논문에서 처음 제안
- GPT도 unlabeled data로 부터 pre-train을 진행한 후 특정 downstream task에 fine-tuning을 하는 모델
- Transformer의 decoder만 사용하는 구조!
7-1. GPT 모델의 특징
- 사전학습에는 대규모의 unlabeled data를 사용하는데 unlabeled data에서 단어 수준 이상의 정보를 얻는 것은 매우 힘듦. 또한 어떤 방법이 유용한 텍스트 표현을 배우는데 효과적인지 불분명함
- 사전학습 이후에도 어떤 방법이 fine-tuning에 가장 효과적인지 불분명
- GPT 논문에서는 unsupervised pre-training과 supervised fine-tuning의 조합을 사용한 접근법을 제안
- 모델을 이미 효과가 검증된 2017년 공개된 transformer를 사용
- fine-tuning에서의 미세조정만으로 다양한 자연어 처리 작업에 적용할 수 있는 범용적인 표현을 사전학습에서 학습하는 것
- GPT는 Transformer의 변형인 multi-layer Transformer decoder만 사용
- 입력 문맥 token에 multi-headed self-attention을 적용한 후, token에 대한 출력 분포를 얻기 위해 position-wise feedforward layer를 적용
- 모델 구조의 변형이 거의 없음
- 모델 구조를 변형하지 않고 linear layer를 마지막에 추가하는 아주 간단한 작업만 수행
7-2. GPT 모델 학습
- unsupervised pre-training
- 대규모 코퍼스에서 unsupervised learning으로 언어 모델을 학습
- transformer 디코더를 사용하여 계속 next token prediction 학습하는 것
- multi-layer Transformer decoder를 사용하여 입력 문맥 token에 multi-head self-attention을 적용한 후, 목표 token에 대한 출력 분포를 얻기 위해 position-wise feedforward layer를 적용
- supervised fine-tuning
- 특정 작업에 대한 데이터로 모델을 fine-tuning
- 파인 튜닝 단계에서는 사전 학습된 모델을 각 task에 맞게 input과 label로 구성된 supervised dataset에 대해 학습
- 결과를 task에 맞는 loss들을 결합
사전 학습은 next token prediction이라는 language modeling으로 진행되었기 때문에 각 downstream task와 input의 모양이 다를 수 밖에 없음
!pip install transformers
import torch
from transformers import pipelinemodel_name = "heegyu/kogpt-j-base"
# pipeline(): 허깅페이스의 Transformers 라이브러리에서 제공하는
# 다양한 자연어 처리 작업을 간편하게 수행할 수 있도록 도와주는 함수
pipe = pipeline("text-generation", model=model_name)
참조: https://huggingface.co/heegyu/kogpt-j-base
print(pipe("안녕하세요", repetition_penalty=1.2, do_sample=True, eos_token_id=1, early_stopping=True, max_new_tokens=128))
- repetition_penalty: 텍스트 생성 과정에서 반복되는 단어 또는 구문의 생성을 억제하기 위한 파라미터
- 특정 단어가 반복될 때 단어의 확률을 감소시키는 방식으로 작동
- 모델이 동일한 단어를 다시 생성하려고 하 때 로그 확률에 페널티를 부여하여 다른 단어를 선택하도록 유도
- 1(페널티를 주지 않음)보다 큰 값을 사용, 1.5가 강한 페널티(텍스트 균형이 맞지 않을 수 있음)
- 특정 단어의 원래 확률이 P라면 반복될 때 확률은 P / 1.2로 줄어듬
- 예) 오늘 날씨는 좋습니다. 오늘 날씨는 맑습니다. => 오늘 날씨는 좋습니다. 하늘을 맑고, 기온은 따뜻합니다.
- do_dample: 텍스트 생성 과정에서 샘플링 방법을 설정. True일 경우 모델은 확률 분포에서 토큰을 무작위로 선택함. 텍스트 생성에 다양성과 창의성을 더 할 수 있음
- 샘플링(Sampling)
- 모델이 예측한 확률 분포에서 무작위로 토큰을 선택하는 방식
- 다양한 결과를 생성할 수 있으며, 예측할 수 없는 창의적인 텍스트를 생성
- 품질이 일관되지 않을 수 있음. 엉뚱하거나 의미 없는 결과를 생성할 가능성이 있음
- 빔 서치(Beam Search)
- 여러 경로를 동시에 고려하여 가장 높은 점수를 가진 경로를 선택하는 방식
- 주어진 빔 폭 내에서 가장 가능성 높은 몇 가지 경로를 추적하며, 최종적으로 가장 점수가 높은 경로를 선택
- 일관되고 논리적인 텍스트를 생성할 수 있음
- 덜 창의적이고 반복적인 텍스트를 생성할 수 있음. 계산 비용이 높음
- 샘플링의 세부 설정
- temperature 확률 분포를 변화시켜 예측된 확률값들을 부드럽게 하거나 날카롭게 만듬
- 높은 값(예: .5): 확률 분포를 평탄하게 만들어 무작위성이 높아짐
- 낮은 값(예: 0.6): 확률 분포를 날카롭게 만들어 결정론적으로 만듦
- top-k 샘플링
- 확률 분포에서 상위 k개의 후보만 고려하는 방법
- 상위 k개의 후보 토큰만 남기고 나미저는 무시한 후, 해당 사이에서 샘플링
- top-p 샘플링
- 누적 확률이 p이상이 되는 후보군을 고려하는 방법
- 후보 토큰을 누적 확률이 p가 되는 지점까지 포함시킨 후, 해당 사이에서 샘플링
- temperature 확률 분포를 변화시켜 예측된 확률값들을 부드럽게 하거나 날카롭게 만듬
- 샘플링(Sampling)
print(pipe("안녕하세요", repetition_penalty=1.2, do_sample=False, eos_token_id=1, early_stopping=True, max_new_tokens=128))
print(pipe("안녕하세요", repetition_penalty=1.5, do_sample=False, eos_token_id=1, early_stopping=True, max_new_tokens=128))
print(pipe("오늘 정부 발표에 따르면, ", repetition_penalty=1.2, do_sample=True, eos_token_id=1, early_stopping=True, max_new_tokens=128))
print(pipe("싸늘하다. 가슴에 비수가 날아와 꽂힌다. ", repetition_penalty=1.2, do_sample=True, eos_token_id=1, early_stopping=True, max_new_tokens=128, min_length=64))
'자연어 처리(NLP)' 카테고리의 다른 글
| 간단한 답변 랭킹 모델 만들기 (0) | 2024.07.01 |
|---|---|
| 한국어 챗봇 (0) | 2024.07.01 |
| 9. LSTM과 GRU (0) | 2024.06.21 |
| 8. CNN text classification (0) | 2024.06.21 |
| 7. cbow text classification (0) | 2024.06.21 |



