이 논문은 "Effective Approaches to Attention-based Neural Machine Translation"이라는 제목의 논문입니다.
작성자는 Minh-Thang Luong, Hieu Pham, 그리고 Christopher D. Manning으로, 스탠포드 대학교 컴퓨터 과학과 소속입니다.
Abstract
논문의 주요 내용은 주의 메커니즘(attention mechanism)을 사용하여 신경 기계 번역(Neural Machine Translation, NMT)을 향상시키는 방법에 대해 다룹니다. attention 메커니즘을 통해 번역 시 원본 문장의 일부에 선택적으로 집중할 수 있게 하여 번역 성능을 개선하고자 합니다. 이 논문에서는 attention 메커니즘의 두 가지 주요 유형인 글로벌 접근법(global approach)과 로컬 접근법(local approach)에 대해 설명하고, 이들의 효과를 영어-독일어 번역 작업에서 실험적으로 입증합니다.
주요 내용은 다음과 같습니다:
1. 신경망 기계 번역(NMT)에서 주의(attention) 메커니즘을 개선하기 위한 두 가지 새로운 접근법을 제안합니다:
- 글로벌(global) attention : 모든 소스 단어에 주목
- 로컬(local) attention : 소스 문장의 일부분에만 주목
2. 영어-독일어 번역 실험에서 제안한 모델의 성능을 평가했습니다.
3. local attention 모델이 가장 좋은 성능을 보였고, non-attention 모델에 비해 최대 5.0 BLEU 점수 향상을 달성했습니다.
4. 영어-독일어 번역에서 앙상블 모델로 WMT'14와 WMT'15에서 새로운 최고 성능을 기록했습니다.
5. 다양한 정렬(alignment) 함수를 비교 분석하고 attention 기반 모델의 장점을 보여주었습니다.
요약하면, 기계 번역에서 주의 메커니즘을 개선한 새로운 모델을 제안하고 그 효과를 실험적으로 입증한 논문입니다.
1. Introduction

신경망 기계 번역(Neural Machine Translation, NMT)은 최근 영어-프랑스어, 영어-독일어 등 대규모 번역 작업에서 최고 수준의 성능을 달성했습니다.
- BLEU 점수 향상:
- attentional 메커니즘을 사용한 모델은 사용하지 않은 모델에 비해 BLEU 점수가 최대 5.0점 향상되었습니다.
- BLEU 점수는 기계 번역의 품질을 평가하는 지표로, 5.0점의 향상은 상당히 큰 개선입니다.
- 영어에서 독일어 번역에서의 성과:
- WMT'14와 WMT'15 두 대회에서 모두 새로운 최고 성능(SOTA, State-of-the-Art)을 달성했습니다.
- 이전의 최고 성능 시스템들(NMT 모델과 n-gram 언어 모델 재순위 시스템 포함)보다 1.0 BLEU 이상 높은 점수를 기록했습니다.
- 기존 기술과의 비교:
- 연구팀의 attention 기반 모델은 드롭아웃과 같은 잘 알려진 기술들을 이미 적용한 non- attention 시스템보다도 우수한 성능을 보였습니다.
- global 접근법과 local 접근법의 장점:
- global 접근법: 기존 모델(Bahdanau et al., 2015)보다 구조적으로 더 단순합니다.
- local 접근법: global모델이나 soft attention 방식보다 계산 비용이 적고, hard attention 방식과 달리 거의 모든 곳에서 미분 가능하여 구현과 학습이 더 쉽습니다.
2. Neural Machine Translation
신경 기계 번역(NMT) 시스템은 소스 문장 x1, ..., xn을 타겟 문장 y1, ..., ym으로 번역하는 조건부 확률 p(y|x)를 직접 모델링하는 신경망입니다. 기본적인 NMT 시스템은 두 가지 주요 구성 요소로 이루어집니다.
- 인코더(Encoder): 각 소스 문장에 대한 표현 s를 계산합니다.
- 디코더(Decoder): 하나의 타겟 단어를 한 번에 생성하며, 조건부 확률을 다음과 같이 분해합니다.

디코더 아키텍처
Decoder에서 이러한 분해를 모델링하기 위한 자연스러운 선택은 순환 신경망(RNN) 아키텍처를 사용하는 것입니다. 최근 NMT 연구에서는 다양한 RNN 아키텍처를 사용하고 있으며, 인코더가 소스 문장 표현 s를 계산하는 방법에서도 차이가 있습니다.
확률 모델링
단어 yj를 디코딩하는 확률은 다음과 같이 매개변수화할 수 있습니다:
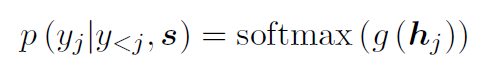
여기서 g는 어휘 크기의 벡터를 출력하는 변환 함수입니다. hj는 추상적으로 다음과 같이 계산된 RNN 히든 유닛입니다:

f는 이전 히든 상태를 주어 현재 히든 상태를 계산하는 함수로, vanilla RNN 유닛, GRU, 또는 LSTM 유닛일 수 있습니다.
본 연구의 접근 방식
본 연구에서는 Sutskever et al. (2014) 및 Luong et al. (2015)를 따르며 스택 LSTM 아키텍처를 사용합니다. LSTM 유닛 정의는 Zaremba et al. (2015)를 따릅니다. 훈련 목표는 다음과 같이 공식화됩니다:

여기서 D는 병렬 훈련 코퍼스입니다.
3. Attention-based Models
신경 기계 번역(NMT)에서 attention-based 모델은 global attention과 local attention으로 분류할 수 있습니다. 이 두 유형은 "attention”"이 모든 소스 위치에 집중되는지, 아니면 일부 소스 위치에만 집중되는지에 따라 다릅니다.
공통점
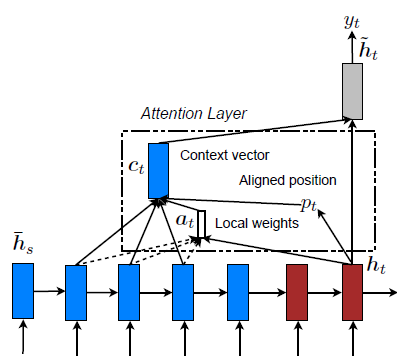
두 모델 모두 디코딩 단계에서 각 시간 단계 t에서 스택 LSTM의 최상위 레이어의 히든 상태 ht를 입력으로 받습니다. 목표는 현재 타겟 단어 yt를 예측하는 데 도움이 되는 관련 소스 정보를 포착하는 컨텍스트 벡터 ct를 도출하는 것입니다.
- attentional hidden state: ℎ 𝑡 와 소스 측 컨텍스트 벡터 𝑐 𝑡 를 결합하여 attention 히든상태 ˜ht 를 생성합니다.

- softmax layer : attention 벡터 ˜를 소프트맥스 레이어로 전달하여 예측 분포를 생성합니다.

아래에서 Global Attention과 Local Attention에 대해 자세하게 서술하겠습니다.
3-1. Global Attention

Global Attention 모델의 핵심 아이디어는 컨텍스트 벡터 ct를 도출할 때 인코더의 모든 히든 상태를 고려하는 것입니다. 이 모델은 현재 타겟 히든 상태 ht와 각 소스 히든 상태 ¯hs 를 비교하여 가변 길이의 정렬 벡터 at를 도출합니다. 이 벡터의 크기는 소스 측의 시간 단계 수와 동일합니다.
Global Attention 모델의 작동 방식
- 정렬 벡터 at 계산: 현재 타겟 히든 상태 ht와 각 소스 히든 상태 ¯hs를 비교하여 정렬 벡터 at를 계산합니다.
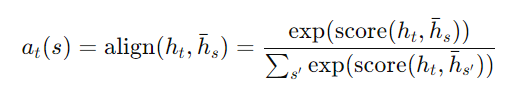
여기서 score는 다음과 같은 내용 기반 함수로 정의됩니다:
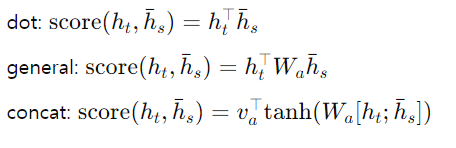
- 컨텍스트 벡터 Ct계산: 정렬 벡터 at를 가중치로 사용하여 모든 소스 히든 상태의 가중 평균을 계산합니다.
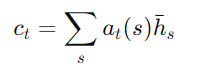
- 어텐션 히든 상태 ˜ht 계산: 타겟 히든 상태 ht와 컨텍스트 벡터 ct를 결합하여 어텐션 히든 상태를 생성합니다.
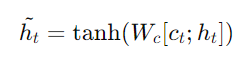
- 예측 분포 계산: 어텐션 히든 상태 ˜ht를 소프트맥스 레이어로 전달하여 예측 분포를 생성합니다.
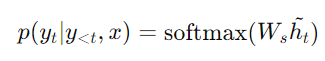
모델 비교: Bahdanau et al. (2015)와의 차이점
- 히든 상태 사용: 저자는 인코더와 디코더의 최상위 LSTM 레이어의 히든 상태를 사용합니다. 반면, Bahdanau et al. (2015)은 양방향 인코더의 순방향 및 역방향 소스 히든 상태와 단방향 디코더의 타겟 히든 상태를 사용합니다.
- 계산 경로 단순화: 저자는 ht → at → ct → ˜h t 의 단순한 경로를 따릅니다. 반면, Bahdanau et al. (2015)은 ht-1 → at → ct → ht 순서로 진행 경로를 따르며, 예측 전에 딥-아웃풋 및 맥스아웃 레이어를 거칩니다.
- 정렬 함수: 저자는 dot, general, concat 등 여러 정렬 함수를 실험하여 가장 효과적인 것을 선택했습니다. 반면, Bahdanau et al. (2015)은 concat 함수만 사용했습니다.
3-2. Local Attention
Global Attention의 한계
Global Attention 모델은 각 타겟 단어마다 소스 측의 모든 단어에 주의를 기울여야 하므로 계산 비용이 많이 들고, 긴 문장이나 문단을 번역할 때 비효율적일 수 있습니다.
Local Attention 메커니즘 제안
이 문제를 해결하기 위해, 우리는 각 타겟 단어에 대해 소스 위치의 작은 부분 집합에만 집중하는 local attention메커니즘을 제안합니다. 이 접근 방식은 이미지 캡션 생성 작업에서 Xu et al. (2015)가 제안한 소프트 및 하드 어텐션 모델 간의 절충안을 참고했습니다.
- soft 어텐션: global attention방식으로, 소스 이미지의 모든 패치에 "부드럽게" 가중치를 부여합니다.
- hard 어텐션: 한 번에 이미지의 하나의 패치에만 주의를 기울이는 방식으로, 추론 시 비용이 적게 들지만, 비차별적이며 학습이 어렵습니다.
Local Attention의 장점
Local Attention 메커니즘은 소스 컨텍스트의 작은 윈도우에만 집중하며, 차별 가능하여 하드 어텐션보다 학습이 쉽습니다. 이 접근 방식은 소프트 어텐션의 높은 계산 비용을 피하면서도, 학습이 용이합니다.
Local Attention 모델의 구체적 작동 방식
- 정렬 위치 ptp_t 생성: 각 타겟 단어 tt에 대해 정렬 위치 ptp_t를 생성합니다.
- 컨텍스트 벡터 ctc_t 도출: [pt−D,pt+D] 윈도우 내의 소스 히든 상태 집합에 대한 가중 평균으로 컨텍스트 벡터 ct를 도출합니다. 여기서 는 경험적으로 선택된 값입니다.
Local Attention은 두 가지 변형이 있습니다:
모노토닉 정렬 (local-m)
모노토닉 정렬에서는 소스와 타겟 시퀀스가 대략적으로 모노토닉하게 정렬된다고 가정하고, 단순히 pt=t로 설정합니다.
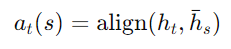
예측 정렬 (local-p)
예측 정렬에서는 모노토닉 정렬을 가정하지 않고, 다음과 같이 정렬 위치를 예측합니다:
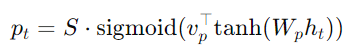
여기서 Wp와 Vp는 모델 파라미터로, 소스 문장의 길이 S에 비례하여 예측 위치 Pt가 설정됩니다. 정렬 가중치는 P 주위의 가우시안 분포를 사용해 설정됩니다:
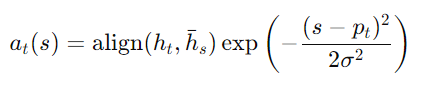
여기서 σ=D2로 설정됩니다. Pt는 실수이며, s는 Pt를 중심으로 한 윈도우 내의 정수입니다.
모델 비교: Bahdanau et al. (2015)와의 차이점
Gregor et al. (2015)는 이미지 생성 작업을 위한 선택적 어텐션 메커니즘을 제안했습니다. 이 접근 방식은 위치와 확대를 다르게 선택할 수 있게 하였지만, 저 모든 타겟 위치에 동일한 "zoom"를 사용하여 공식을 단순화하고도 좋은 성능을 달성했습니다.
3-3. Input-feeding Approach
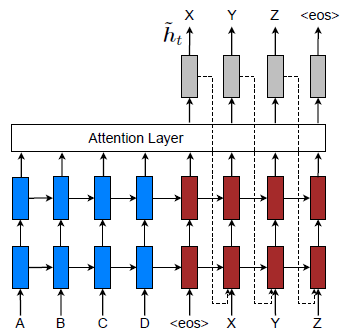
- 제안된 global 및 local 접근 방식에서 attentional를 기울이는 결정이 독립적으로 이루어지는 것은 최적이 아닙니다.
- 표준 기계 번역에서는 번역 과정 중 어떤 소스 단어가 번역되었는지 추적하기 위해 커버리지 셋을 유지합니다.
- attentional NMT에서도 과거 정렬 정보를 고려하여 정렬 결정을 공동으로 내려야 합니다.
- 이를 해결하기 위해 '입력 피딩 접근법'을 제안합니다. 이는 attentional 벡터를 다음 시간 단계의 입력과 연결하는 방식입니다.
- 이 접근법의 효과:
- 모델이 이전 정렬 선택을 완전히 인식하게 됩니다.
- 수평 및 수직으로 매우 깊은 네트워크를 만듭니다.
- 다른 연구와의 비교:
- Bahdanau et al. (2015)의 방법도 '커버리지' 효과를 달성할 수 있지만, 그 유용성에 대한 분석은 없었습니다.
- 제안된 접근법은 더 일반적이며, non-attentional 모델을 포함한 일반적인 스태킹 순환 아키텍처에 적용할 수 있습니다.
- Xu et al. (2015)의 doubly attentional 접근법과 달리, 제안된 방법은 모델이 적절한 attentional constraints을 결정할 수 있는 유연성을 제공합니다.
4. Attention-based Models
- 평가 대상: WMT 번역 태스크에서 영어와 독일어 간의 양방향 번역
- 데이터셋:
- Development Set(하이퍼파라미터 선택용): newstest2013 (3000문장)
- 테스트 세트:
- newstest2014 (2737문장)
- newstest2015 (2169문장)
- 평가 지표: 대소문자를 구분하는 BLEU 점수 사용
- 두 가지 유형의 BLEU 점수 보고:
- a) Tokenized BLEU: 기존 NMT 작업과 비교하기 위함.
- b) NIST BLEU: WMT 결과와 비교하기 위함.
4-1. Training Details
- 훈련 데이터:
- WMT'14 훈련 데이터 사용 (4.5M 문장 쌍, 116M 영어 단어, 110M 독일어 단어)
- 상위 50K 빈도 단어로 어휘 제한, 나머지는 <unk> 토큰으로 변환
- 전처리:
- 50단어 초과 문장 쌍 제외
- 미니배치 셔플링
- 모델 구조:
- 4층 스태킹 LSTM, 각 층 1000 셀
- 1000차원 임베딩
- 훈련 설정:
- 파라미터 초기화: [-0.1, 0.1] 균일 분포
- 10 에폭 훈련 (드롭아웃 모델은 12 에폭)
- SGD 최적화
- 학습률: 초기 1, 5 에폭 후 매 에폭마다 절반으로 감소
- 미니배치 크기: 128
- 정규화된 그래디언트 norm이 5 초과 시 rescaling
- LSTM에 0.2 확률의 드롭아웃 적용
- local 어텐션 모델:
- 윈도우 크기 D = 10
- 구현 및 성능:
- MATLAB으로 구현
- Tesla K40 GPU 사용 시 초당 1K 타겟 단어 처리
- 모델 완전 훈련에 7-10일 소요
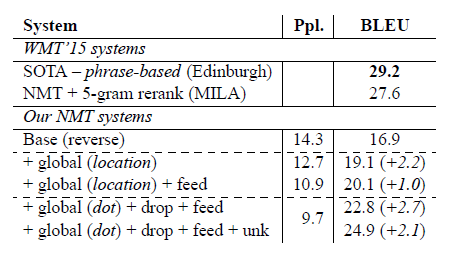
4-2. English-German Results

- 비교 대상:
- WMT'14 우승 시스템 (Buck et al., 2014)
- Jean et al. (2015)의 end-to-end NMT 시스템 (당시 SOTA)
- 성능 개선 요소:
- 소스 문장 역전: +1.3 BLEU
- 드롭아웃 사용: +1.4 BLEU
- global attention 접근법: +2.8 BLEU
- 입력 피딩 접근법: +1.3 BLEU
- 예측적 정렬을 사용한 local attention 모델: +0.9 BLEU
- 총 개선:
- 비주의 집중 기준선 대비 +5.0 BLEU 향상
- unknown replacement technique 적용: +1.9 BLEU 추가 향상
- 최종 결과:
- 8개 다양한 모델 앙상블: 23.0 BLEU (새로운 SOTA)
- Jean et al. (2015) 대비 +1.4 BLEU 향상
- WMT'15 최신 결과:
- newstest2015에서 25.9 BLEU 달성 (새로운 SOTA)
- 기존 최고 시스템 대비 +1.0 BLEU 향상
- 주요 관찰:
- 복잡도(perplexity)가 번역 품질과 강한 상관관계를 보임
- attentional models이 unknown works에 대해 유용한 정렬을 학습함

4-3. German-English Results
- 실험 개요:
- WMT'15 독일어에서 영어로의 번역 작업
- 제안된 시스템이 아직 SOTA(최첨단) 성능에는 미치지 못했지만, 상당한 개선을 보여줌
- 성능 개선 요소:
- attentional 메커니즘: +2.2 BLEU
- 입력 피딩 접근법: 최대 +1.0 BLEU 추가
- 개선된 정렬 함수(내용 기반 내적)와 드롭아웃: +2.7 BLEU
- unknown replacement technique: +2.1 BLEU
- 주요 관찰:
- 각 개선 요소가 점진적으로 BLEU 점수를 향상시킴
- attentional mechanism이 희귀 단어 정렬에 유용함을 입증
- 결과의 의미:
- 제안된 접근법들의 효과성을 입증
- 특히 attentional mechanism, 입력 피딩, 개선된 정렬 함수가 성능 향상에 크게 기여
- unknown replacement technique의 효과가 큼을 보여줌
5. Analysis
모든 결과는 영어-독일어 newstest2014 데이터셋을 기준으로 보고됩니다.
5-1. Learning curves
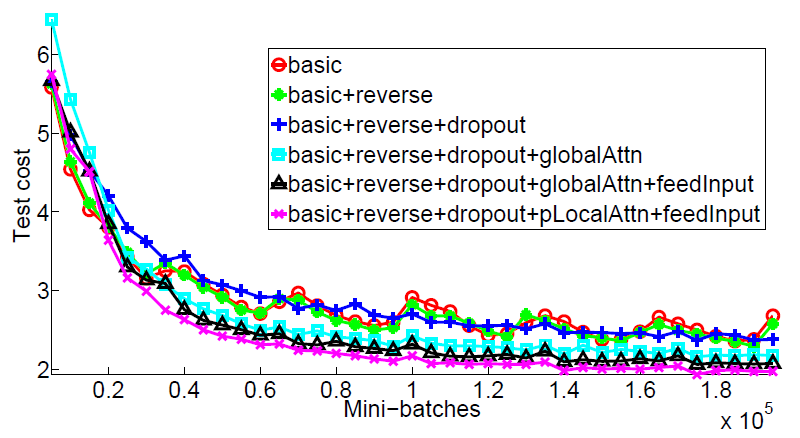
모델 성능 차이:
- 비어텐션 모델과 어텐션 모델 간의 명확한 성능 차이가 있음을 확인했습니다. 어텐션 모델은 비어텐션 모델에 비해 더 낮은 테스트 비용을 보였습니다.
Input-Feeding 접근 방식:
- Input-Feeding 접근 방식을 적용한 모델은 테스트 비용을 더욱 효과적으로 낮추는 능력을 보여주었습니다.
드롭아웃을 적용한 비어텐션 모델:
- 드롭아웃을 적용한 비어텐션 모델(파란색 + 곡선)은 초기 학습 속도가 다른 드롭아웃을 적용하지 않은 모델보다 느렸으나, 시간이 지남에 따라 테스트 오류를 최소화하는 데 더 견고함을 보였습니다.
5-2. Effects of Translating Long Sentences
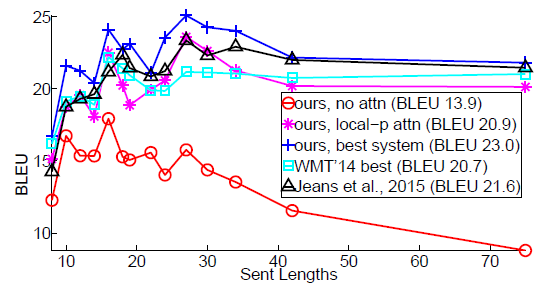
- 긴 문장 처리 성능:
- 어텐션 모델은 문장이 길어짐에 따라 품질이 저하되지 않는다는 점에서 비어텐션 모델보다 우수했습니다.
- 최고 성능 모델:
- 우리의 최고 성능 모델(파란색 + 곡선)은 모든 길이의 문장에서 다른 시스템보다 뛰어난 성능을 보였습니다.
5-3. Choices of Attentional Architectures
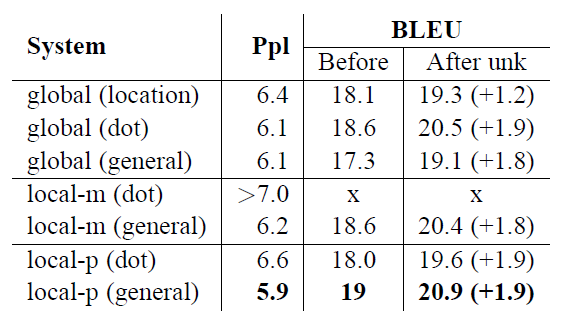
- 분석 대상:
- attention 모델: 글로(global), 로컬-m(local-m), 로컬-p(local-p)
- 정렬 함수: 위치 기반(location), 내적(dot), 일반(general), 연결(concat)
- 분석 결과 (Table 4 참조): a) 위치 기반 함수:
- 좋은 정렬을 학습하지 못함
- 미지어 대체 시 작은 이득만 얻음
- concat 구현이 좋은 성능을 내지 못함 (추가 분석 필요)
- dot은 global attention의 집중에서 잘 작동
- general은 local attention의 집중에서 더 나은 성능
- 예측적 정렬을 사용한 local attention 모델(local-p)이 복잡도(perplexity)와 BLEU 점수 모두에서 최고 성능
5-4. Alignment Quality
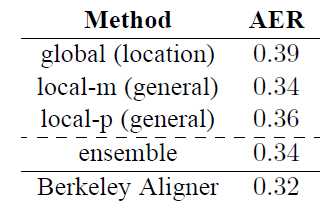
- 평가 방법:
- 정렬 오류율(AER, Alignment Error Rate) 메트릭 사용
- RWTH에서 제공한 508개의 영어-독일어 Europarl 문장에 대한 골드 정렬 데이터 활용
- "force”" 디코딩을 통해 참조 번역과 일치하는 번역 생성
- 각 타겟 단어에 대해 가장 높은 정렬 가중치를 가진 소스 단어만 선택하여 일대일 정렬 추출
- 결과:
- Berkeley aligner의 일대다 정렬과 비슷한 수준의 AER 달성
- local attention 모델이 global attention 모델보다 낮은 AER 달성
- ensemble(앙상블) 모델의 AER은 좋지만 local-m 모델의 AER보다는 나쁨
- AER과 번역 점수가 잘 상관되지 않는다는 기존 관찰 확인 (Fraser and Marcu, 2007)
5-5. Sample Translations
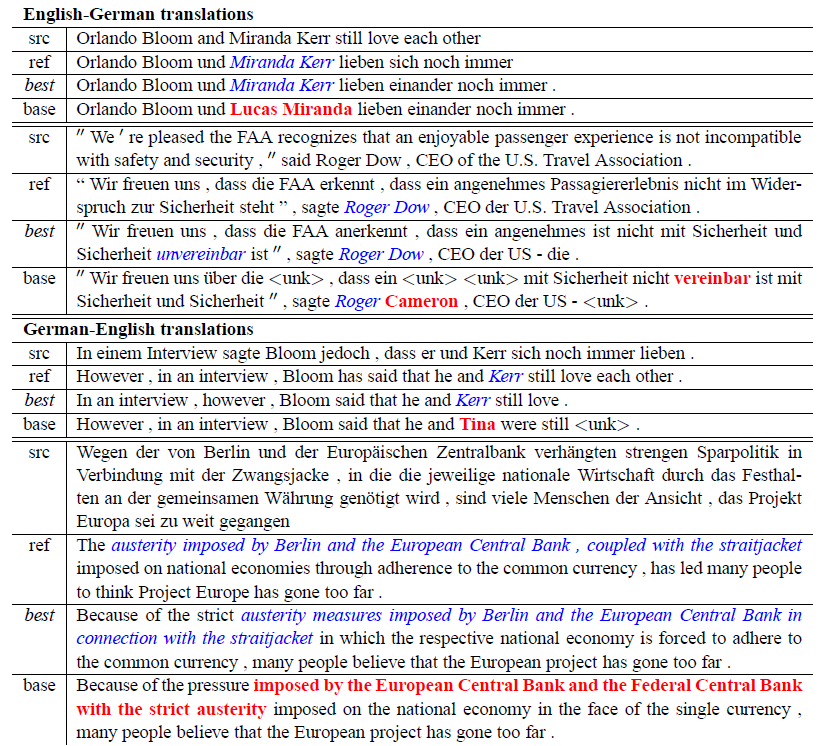
- 원문(src)
- 인간 번역(ref)
- 저자의 최고 모델 번역(best)
- non attention 모델 번역(base)
- 올바른 번역 부분은 이탤릭체 표시
- 잘못된 부분은 굵게 표시
- 분석 대상:
- Table 5에 제시된 양방향(영어-독일어, 독일어-영어) 번역 예시
- 주요 관찰: a) 고유명사 번역:
- attentional 모델: "Miranda Kerr", "Roger Dow" 등의 이름을 정확히 번역
- Non-attentional 모델: 언어 모델 관점에서 그럴듯한 이름을 생성하지만, 원문과의 직접적 연결이 부족해 정확한 번역 실패
- 예시: "not incompatible" (이중 부정)
- attention 모델: "nicht ... unvereinbar" (정확한 번역)
- non-attention 모델: "nicht vereinbar" (의미가 반대로 됨, "not compatible")
- attention모델이 긴 문장 번역에서 우수성을 보임
6. Conclusion
이 논문에서는 두 가지 간단하고 효과적인 어텐션 메커니즘을 제안합니다:
- 모든 소스 위치를 항상 고려하는 global 접근법.
- 한 번에 일부 소스 위치에만 집중하는 local 접근법입니다.
이러한 모델들을 영어와 독일어 사이의 WMT 번역 작업에서 실험하여 그 효과를 평가하였습니다.
- 실험 및 결과:
- WMT 영어-독일어 양방향 번역 작업에서 테스트
- local attention의 모델: 드롭아웃 등의 기존 기술을 적용한 non-attentional 모델 대비 최대 5.0 BLEU 점수 향상
- 영어에서 독일어 번역: 앙상블 모델이 WMT'14와 WMT'15에서 새로운 최고 성능 달성 (기존 최고 시스템 대비 1.0 BLEU 이상 향상)
- 분석 결과:
- 다양한 정렬 함수 비교 및 각 attentional 모델에 적합한 함수 파악
- attention-based NMT 모델이 non-attentional 모델보다 여러 측면에서 우수함을 확인 예: 이름 번역, 긴 문장 처리 등
- 의의:
- 새로운 attentional 메커니즘 제안: 간단하면서도 효과적인 global 및 local attention의 attentional 메커니즘을 개발
- 성능 향상: 기존 최고 성능을 크게 뛰어넘는 결과 달성
- 다양한 분석: 정렬 함수 비교, 모델 성능 분석 등을 통해 attentional 메커니즘의 효과성을 다각도로 입증
- 실용적 개선: 이름 번역, 긴 문장 처리 등 실제 번역에서 중요한 과제들에 대한 개선 확인
Reference
논문 출저: Effective Approaches to Attention-based Neural Machine Translation
'논문 리뷰' 카테고리의 다른 글
| [논문 리뷰] Convolutional LSTM Network: A Machine LearningApproach for Precipitation Nowcasting (1) | 2024.08.12 |
|---|---|
| 논문리뷰 SSD: Single Shot MultiBox Detector (1) | 2024.08.05 |
| [논문 리뷰] BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding (0) | 2024.07.08 |
| [논문 리뷰] Attention Is All You Need (0) | 2024.07.08 |
| [논문 리뷰] Deep contextualized word representations (0) | 2024.07.08 |



