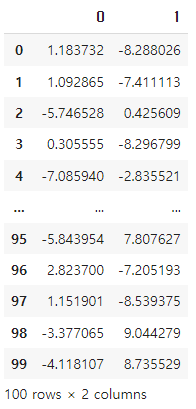
영어 한글
---------------------- --------------------------
ID 고객 아이디
Year_Birth 출생 연도
Education 학력
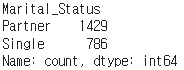
Marital_Status 결혼 여부
Income 소득
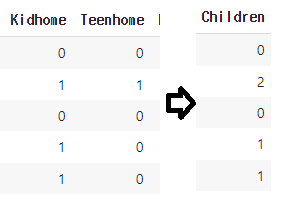
Kidhome 어린이 수
Teenhome 청소년 수
Dt_Customer 고객 등록일
Recency 마지막 구매일로부터 경과일
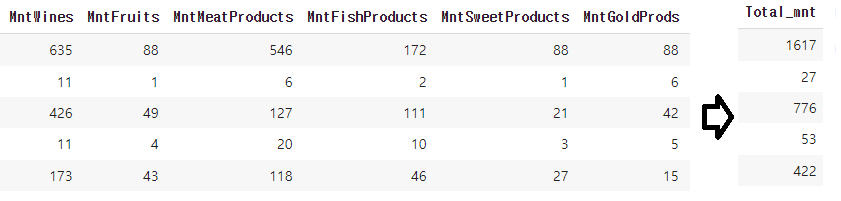
MntWines 와인 구매액
MntFruits 과일 구매액
MntMeatProducts 육류 제품 구매액
MntFishProducts 어류 제품 구매액
MntSweetProducts 단맛 제품 구매액
MntGoldProds 골드 제품 구매액
NumDealsPurchases 할인 행사 구매 수
NumWebPurchases 웹에서의 구매 수
NumCatalogPurchases 카탈로그에서의 구매 수
NumStorePurchases 매장에서의 구매 수
NumWebVisitsMonth 월별 웹 방문 수
Complain 불만 여부
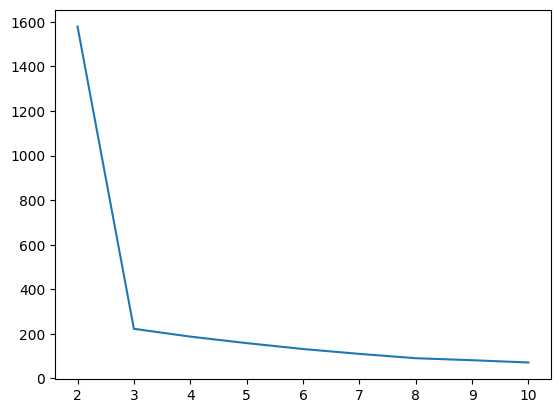
k개의 중심점을 찍은 후에 이 중심점에서 각 점간의 거리의 합이 가장 최소화가 되는 중심점 k의 위치를 찾고, 이 중심점에서 가까운 점들을 중심점을 기준으로 묶는 알고리즘
k개의 클러스터의 수는 정해줘야 함
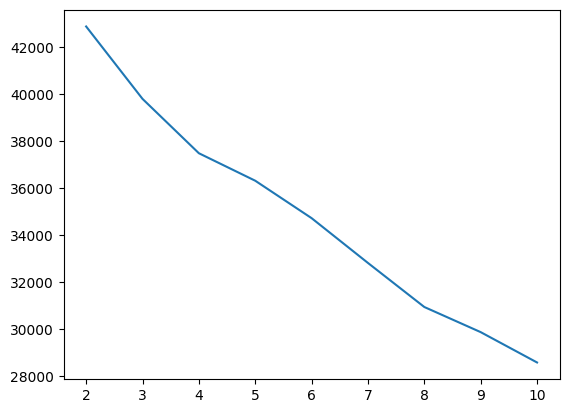
inertia_list = []
for i in range(2, 11):
km = KMeans(n_clusters=i, random_state=2024)
km.fit(ss_df)
inertia_list.append(km.inertia_)
sns.lineplot(x=range(2, 11), y=inertia_list)
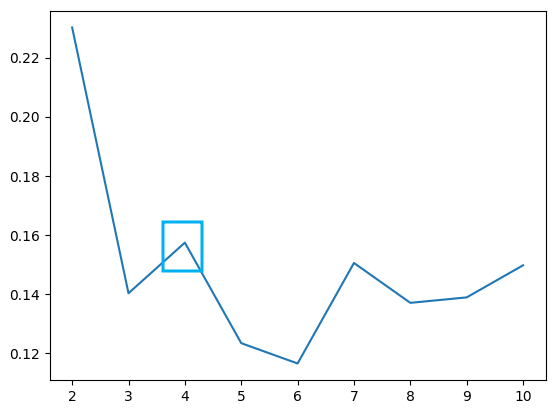
4. 실루엣 스코어
군집화의 품질을 평가하는 지표로, 각 데이터 포인트가 자신이 속한 군집과 얼마나 잘 맞는지, 그리고 다른 군집과 얼마나 잘 구분되는지를 측정
-1에서 1사이의 값을 가지며, 값이 클수록 군집화의 품질이 높음을 나타냄
from sklearn.metrics import silhouette_score
score = []
for i in range(2, 11): # 최소 2개의 그룹으론 나눠지기 때문에 2부터 시작
km = KMeans(n_clusters=i, random_state=2024)
km.fit(ss_df)
pred = km.predict(ss_df)
score.append(silhouette_score(ss_df, pred))
# 스코어 수가 가장 큰 x값이 cluster의 k값으로 설정하는 것이 가장 깔끔함
sns.lineplot(x=range(2, 11), y=score)
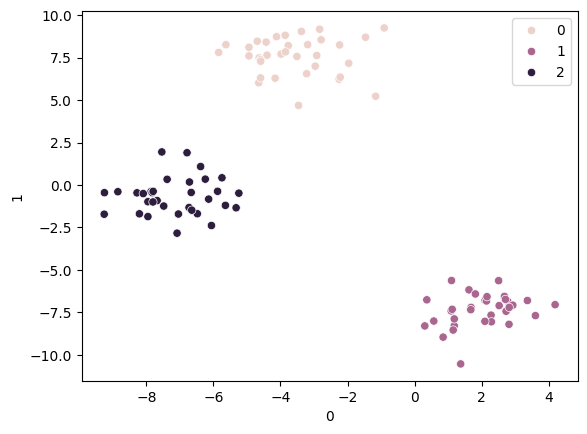
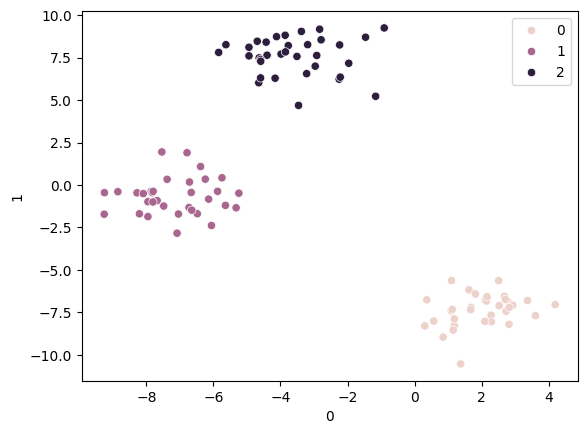
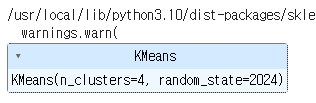
km = KMeans(n_clusters=4, random_state=2024)
# 학습
km.fit(ss_df)
# 예측
pred = km.predict(ss_df)
pred
# 해당 데이터에 파생변수로 군집 번호를 생성하기
mkt_df['label'] = pred
mkt_df