
1. Rent 데이터셋
import numpy as np
import pandas as pd
import seaborn as snsrent_df = pd.read_csv('/content/drive/MyDrive/KDT/6.머신러닝과 딥러닝/Data/rent.csv')
rent_df

rent_df.info()
Posted On: 매물 등록 날짜
BHK: 베드, 홀, 키친의 개수
Rent: 렌트비
Size: 집 크기
Floor: 총 층수 중 몇층
Area Type: 공용공간을 포함하는지, 집의 면적만 포함하는지
Area Locality: 지역
City: 도시
Furnishing Status: 풀옵션 여부
Tenant Preferred: 선호하는 가족형태
Bathroom: 화장실 개수
Point of Contact: 연락할 곳# 숫자형 열에 대한 기술 통계량을 제공합니다.
# 평균, 표준편차, 최소값, 25%, 50%, 75% 백분위수 등이 포함됩니다
# round는 나타내고자 하는 소수점 자리를 설정할 수 있습니다
round(rent_df.describe(), 2)
# sns.displot() 를 통해 컬럼에 있는 데이터를 시각화 할 수 있습니다
sns.displot(rent_df['BHK'])
sns.displot(rent_df['Rent'])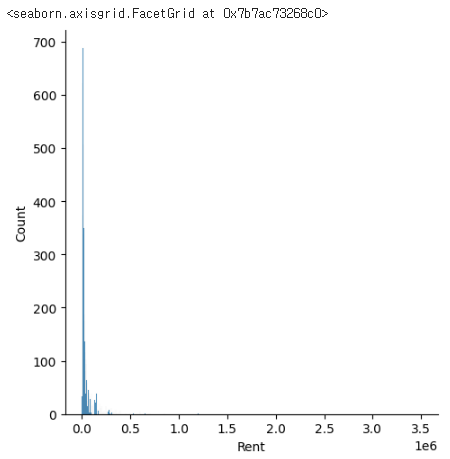
rent_df['Rent'].sort_values()
# sns.boxplot() 을 통해 컬럼에 있는 데이터의 연속성을 확인할 수 있는데
# 너무 동떨어져 있으면 데이터의 신뢰성이 떨어진다고 볼 수 있습니다
sns.boxplot(y=rent_df['Rent'])
sns.boxplot(y=rent_df['BHK'])
# 데이터프레임에서 각 열별로 누락된 값(결측지)의 비율을 계산해서 나타내 줍니다
rent_df.isna().mean()
# BHK에 있는 결측치 데이터를 삭제
# 3개 삭제 됨
rent_df.dropna(subset=['BHK'])

# Size가 Null인 애들
na_index = rent_df[rent_df['Size'].isna()].index
na_index
rent_df['Size'].fillna(rent_df['Size'].median()).loc[na_index]
# 데이터 프레임에서 결측지를 해당 열의 중앙값(median)으로 대체해 줍니다
rent_df = rent_df.fillna(rent_df.median(numeric_only=True))rent_df.info()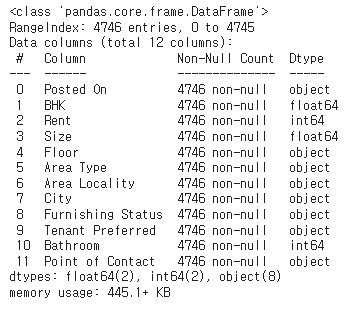
rent_df['Floor'].value_counts()
# 데이터프레임에서 해당 열(컬럼)에 속하는 고유한 값의 개수를 알려줍니다
rent_df['Area Type'].value_counts()
# unique() 는 데이터프레임에서 해당 열(컬럼)에 해당하는 고유한 값(value) 값을 알려줍니다
rent_df['Area Type'].unique()
# nunique() 는 데이터프레임에서 해당 열(컬럼)에 해당하는 개수(counts)를 알려줍니다
rent_df['Area Type'].nunique()
# 반복문을 이용하여 dtype이 object형인 컬럼들을 라벨인코딩하기 위해 중복데이터를 제외한 데이터 개수
for i in ['Floor', 'Area Type', 'Area Locality', 'City', 'Furnishing Status', 'Tenant Preferred', 'Point of Contact']:
print(i, rent_df[i].nunique())
# 모델 학습에 있어서 빼는 것이 좋다고 판단한 피쳐들 제거하기
rent_df.drop(['Posted On', 'Floor', 'Area Locality', 'Tenant Preferred', 'Point of Contact'], axis=1, inplace=True)
rent_df.info()
# object형 컬럼 원 핫 인코딩 하기
rent_df = pd.get_dummies(rent_df, columns=['Area Type', 'City', 'Furnishing Status'])
rent_df.head()
X = rent_df.drop('Rent', axis=1) # 독립변수
y = rent_df['Rent'] # 종속변수from sklearn.model_selection import train_test_splitX_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=2024)
X_train.shape, X_test.shape
y_train.shape, y_test.shape
2. 선형 회귀(Linear Regression)
- 선형 회귀는 데이터를 가장 잘 설명할 수 있는 직선을 찾는 머신러닝 알고리즘입니다. 단순 선형 회귀와 다중 선형 회귀 두 가지 종류가 있습니다.
- 단순 선형 회귀: 단일 독립 변수와 종속 변수 간의 관계를 분석
- 예) 면적과 월세 간의 관계 분석
- 다중 선형 회귀: 여러 개의 독립 변수와 종속 변수 간의 관계를 분석
- 예) 면적, 방 개수, 욕실 개수, 위치 등 여러 요소가 월세에 미치는 영향 분석
- 단순 선형 회귀: 단일 독립 변수와 종속 변수 간의 관계를 분석
from sklearn.linear_model import LinearRegressionlr = LinearRegression()lr.fit(X_train, y_train)
pred = lr.predict(X_test)
3. 평가 지표 만들기
3-1. MSE(Mean Squared Error)
- 예측값과 실제값의 차이에 대한 제곱에 대해 평균을 낸 값

p = np.array([3, 4, 5]) # 에측값
act = np.array([1, 2, 3]) # 실제값def my_mse(pred, actual):
return ((pred - actual) ** 2).mean()my_mse(p, act)
3-2. MSE(Mean Squared Error)
- 예측값과 실제값의 차이에 대한 절대값에 대해 평균을 낸 값

def my_mae(pred, actual):
return np.abs(pred - actual).mean()my_mae(p, act)
3-3. MSE(Mean Squared Error)
- 예측값과 실제값의 차이에 대한 제곱에 대해 평균을 낸 후 루트를 씌운 값
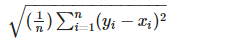
def my_rmse(pred, actual):
return np.sqrt(my_mse(pred, actual))my_rmse(p, act)
from sklearn.metrics import mean_absolute_error, mean_squared_errormean_absolute_error(p, act)
mean_squared_error(p, act)
mean_squared_error(p, act, squared=False) # RMSE
3-4. 데이터에 평가 지표 적용하기
mean_squared_error(y_test, pred)
mean_absolute_error(y_test, pred)
mean_squared_error(y_test, pred, squared=False)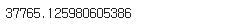
# 아웃라이어로 생각되는 데이터를 삭제
X_train.drop(1837, inplace=True)
y_train.drop(1837, inplace=True)lr.fit(X_train, y_train)
pred = lr.predict(X_test)mean_squared_error(y_test, pred, squared=False)
# 1837 삭제 전: 37765.125980605386
# 1837 삭제 후 37731.275512059074
37765.125980605386 - 37731.275512059074
# 33.850468546312186 만큼 오차가 줄었음'머신러닝 & 딥러닝' 카테고리의 다른 글
| 7. 로지스틱 회귀 (0) | 2024.06.12 |
|---|---|
| 6. 의사 결정 나무 (1) | 2024.06.11 |
| 4. 타이타닉 데이터셋 (0) | 2024.06.10 |
| 3. 아이리스 데이터셋 (1) | 2024.06.10 |
| 2. 사이킷런(Scikit-Learn) (0) | 2024.06.10 |



