
1. 문제 정의
- 문제에 대한 솔루션이 있어야 하고 명확하고 구체적일수록 알맞는 자연어처리 기술을 찾을 수 있음
2. 데이터 수집 및 분석
- 다양한 학습데이터를 수집하기 위해 공개된 데이터셋, 유로 데이터셋 또는 웹 크롤링을 사용하여 수집
- https://paperswithcode.com/datasets?mod=texts&task=question-answering
- 웹크롤링을 통해 데이터를 수집했다면 EDA(탐색적 데이터 분석) 및 분석 작업을 통해 데이터를 철저하게 검증해야 함
- 레이블이 필요하다면 수집한 데이터에 레이블을 붙여야 함
3. 데이터 전처리
- 학습에 용이하게 데이터를 수정/보완하는 작업
- 자연어처리 진행 과정에서 데이터가 차지하는 비중이 매우 높기 때문에 데이터를 수집하고 전처리하는 과정이 매우 중요함
- 토큰화(Tokenization): 주어진 데이터셋에서 문장이나 문서들을 토큰이라 불리는 단위로 나누는 작업
- 정제(Cleaning): 갖고 있는 데이터셋으로부터 노이즈 데이터(이상치, 편향 등)를 제거하는 작업
- 정규화(Normalization): 표현 방법이 다른 데이터들을 통합시켜서 같은 항목으로 합침
3-1. 토큰화(Tokenization)
- 토큰의 단위는 자연어 내에서 의미를 가지는 최소 단위로 정의
- 토큰화 작업은 주어진 코퍼스 내 자연어 문장들을 토큰이라 불리는 최소 단위로 나누는 작업
- 코퍼스(Corpus): 자연어처리 연구나 애플리케이션 활용을 염두에 두고 수집된 텍스트 데이터셋을 의미
3-2. 토큰화 과정의 필요성
- 언어 모델의 자연어 이해 능력 향상
- 다양한 자연어를 효율적으로 표현 가능
- 중복을 제거한 대규모 자연어 코퍼스 내 토큰의 집합(단어 사전) 사용
- 적절한 정보량을 내포하면서 전체 단어사전의 개수가 많아지지 않도록 토큰의 단위를 잘 정의해야 함
- 상황에 따라 다르지만, 일반적인 자연어처리 작업에서 단어 사전의 규모는 약 10,000 ~ 50,000개 정도로 구성(현대 한글의 글자 수는 11,172개)
3-3. 토큰화 방법
- 문장 토큰화: 토큰의 기준을 문장으로 하는 토큰화 방법
- 문장의 끝에 오는 문장 부호를 기준으로 코퍼스를 잘라냄(. 또는 ! 또는 ?)
- 단어 토큰화: 토큰의 기준을 단어로 하는 토큰화 방법
- 보편적으로 구분기호를 가지고 텍스트를 나누게 되며, 기본적으로 공백을 구분자로 사용
- 한국어의 경우 교착어이기 때문에 공백으로 단어 토큰화를 하면 성능이 좋지 않음
- 새로운 단어가 추가될수록 단어 사전의 크기가 계속 증가
- OOV(Out of Vocabulary) 문제 발생
- 문자 토큰화: 토큰의 기준을 문자로 하는 토큰화 방법
- 단어 토큰화의 한계점들을 해결하기 위한 방법
- 영어는 26개의 알파벳에 따라 분리, 한국어는 자음 19개와 모음 21개의 글자에 따라 분리
- 문장 하나를 생성하는 데 너무 많은 추론이 필요함
- 단어 사전은 작지만 모델의 예측 시간에 문제가 생길 수 있음
- 서브워드 토큰화: 토큰의 기준을 서브워드로 하는 토큰화 방법
- 단어 토큰화와 문자 토큰화의 한계점을 해결하기 위한 방법
- 문자 토큰화의 확장된 버전으로 토큰의 단위를 n개의 문자로 정의하고, 해당 기준에 따라 텍스트를 분절하는 방법
- 형태소 분절 기반의 서브워드 토큰화로 확장될 수 있어 한국어에서도 좋은 성능을 가짐
- 서브 워드를 만드는 알고리즘 중에서 가장 유명한 것이 BPE
4. 서브워트 토큰화
4-1. 서브워드(subword)
- 단어보다 더 작은 의미의 단위
- 단어를 여러 서브워드로 분리해서 단어 사전을 구축하겠다는 토큰화 방법
- 신조어에서 주로 발생하는 OOV 문제를 완화
- 예) Birthday = birth + day, 아침밥 = 아침 + 밥
4-2. BPE(Byte Pair Encoding)
- 코퍼스 내 단어의 등장 빈도에 따라 서브워드를 구축하는데 사용
- 2016년 [Neural Machine Translation of Rare Words with Subword Units]논문에서 제안
- 글자단위에서 점진적으로 서브워드 집합을 만들어내는 Bottom-up 방식의 접근 방식으로 자연어 코퍼스에 있는 모든 단어들을 글자 단위로 분리한 뒤에, 등장 빈도에 따라 글자들을 서브워드로 통합하는 방식
- https://arxiv.org/abs/1508.07909
Neural Machine Translation of Rare Words with Subword Units
Neural machine translation (NMT) models typically operate with a fixed vocabulary, but translation is an open-vocabulary problem. Previous work addresses the translation of out-of-vocabulary words by backing off to a dictionary. In this paper, we introduce
arxiv.org
4-3. WordPiece Tokenizer
- 구글이 2016년도Google's Neural Machine Translation System Bridging the Gap between Human and Machine Translation 논문에 처음 공개한 BPE의 변형 알고리즘
- 병합할 두 문자가 있을 때, 각각의 문자가 따로 있을때가 더 중요한지, 병합되었을 때가 더 중요한지 차이점을 둠
- GPT 모델과 같은 자연어 생성모델의 경우에는 BPE 알고리즘을 사용
- BERT, ELECTRA와 같은 자연어 이해 모델에서는 WordPiece Tokenizer를 주로 사용
- https://arxiv.org/abs/1609.08144
Google's Neural Machine Translation System: Bridging the Gap between Human and Machine Translation
Neural Machine Translation (NMT) is an end-to-end learning approach for automated translation, with the potential to overcome many of the weaknesses of conventional phrase-based translation systems. Unfortunately, NMT systems are known to be computationall
arxiv.org
5. 정제(Cleaning)
- 토큰화 작업에 방해가 되는 부분들을 필터링하거나 토큰화 작업 이후에도 여전히 남아있는 노이즈들을 제거하기 위해 지속적으로 이뤄지는 전처리 과정
- 어떤 특성이 노이즈인지 판단하거나, 모든 노이즈를 완벽하게 제거하는 것은 어렵기 때문에 일종의 합의점을 찾아야 함
5-1. 정제 작업의 종류
- 불용어(Stopword) 처리
- 불용어의 정의는 가변적이기 때문에 추가하고 싶은 불용어가 있다면 직접 정의할 수 있음
- 보편적으로 선택할 수 있는 한국어 불용어 리스트(https://www.ranks.nl/stopwords/korean)
- 불필요한 태그 및 특수 문자 제거
- 코퍼스 내 등장 빈도가 적은 단어 제거
- 코퍼스 내 단어들의 빈도를 분석하여 분포를 보고 특정 threshold를 설정한 후, 해당 threshold 아래의 단어들을 필터링하는 방식으로 정제
5-2. 정제 과정에서 유의해야 할 점
- @와 같은 특수 문자는 일반적으로 작업에서는 정보량이 적은 토큰일 수 있지만 이메일과 관련한 내용을 판단해야 하는 작업에서는 유용한 토큰으로 사용될 수 있음
- 자연어처리 작업에서 데이터를 수집한 이후에는 항상 목적에 맞지 않은 노이즈가 있진 않은지 검사하고 발견한 노이즈를 정제하기 위한 노력이 필요
6. 정규화(Normalization)
- 일반적인 ML 작업에서 데이터 정규화는 학습 데이터의 값들이 적당한 범위를 유지하도록 데이터의 범위를 변환하거나 스케일링하는 과정
- 정규화 목표는 모든 데이터가 같은 정도의 스케일로 반영되도록 하는 것
- 자연어처리 정규화의 핵심은 표현 방법이 다른 단어들을 통합시켜서 같은 단어로 만들어 주는 과정
6-1. 정규화 작업이 필요한 이유
- 이상적으로 단어 사전내의 단어 토큰들이 모두 중요하게 고려되길 원함
- 자연어의 특성상 의미가 같은데 표기가 다른 단어들이 있고, 의미는 같지만 사용 빈도가 낮은 동의어들은 학습에 유용하게 활용되지 않을 수 있음
- 의미가 같지만 표기가 다른 단어들을 통합할 수 있다면, 통합된 단어의 사용 빈도가 높아질 것이고, 빈도가 낮은 단어들의 중요도가 높아질 수 있음
6-2. 정규화 작업의 종류
- 어간 추출, 표제어 추출
- 어간 추출: 형태학적 분석을 단순화한 버전으로, 정해진 규칙만 보고 단어의 어미를 자르는 어림짐작의 작업
- 표제어 추출: 단어들이 다른 형태를 가지더라도, 그 뿌리 단어를 찾아가서 단어의 개수를 줄일 수 있는지 판단하는 방법
- 대소문자 통합
- 대문자와 소문자가 구분되어야 하는 경우도 있음. 무작정 소문자로 통합해서는 안됨.예) US(미국) -> us(우리)
6-3. 정규화 시 유의할 점
- 규칙이 너무 엄격한 정규화 방법은 부작용이 심해 학습에 악영향을 줄 수 있음
- 원본 의미를 최대한 유지하는 것이 학습에 도움이 됨
- 대화에서 사용하는 의미가 비슷한 이모티콘들을 통합하는 정규화 하는 작업이 필요
7. 한국어 데이터 전처리
7-1. 한국어의 특성
- 영어는 합성어나 줄임말에 대한 예외처리만 한다면 띄어쓰기를 기준으로 하는 토큰화 작업으로도 어느 정도의 성능을 보장할 수 있음
- 한국어에는 조사나 어미가 발달되어 있기 때문에 띄어쓰기만으로 단어를 분리하면 의미적인 훼손이 일어날 수 있음
- 띄어쓰기 단위가 되는 단위를 '어절' 이라고 하는데, 어절 토큰화와 단어 토큰화가 같지 않기 때문
7-2. 형태소 분석
- 형태소를 비롯하여, 어근/접두사/접미사/품사 등 다양한 언어적 속성의 구조를 파악하는 것을 의미
- 형태소 분석 과정은 한국어 단어에서 형태소를 추출하여 분리하는 작업이며, 이후에 필요에 따라 사전 정의된 품사를 해당 단어에 태깅하는 작업을 하기도 함
- 태깅: 형태소의 뜻과 문맥을 고려하여 품사를 매핑하는 것
8. 자연어 전처리 실습
# 웹 스크레핑을 통해 뉴스 기사를 수집하고 분석하는데 사용되는 라이브러리
!pip install newspaper3kimport newspaper
# 라이브러리 지원 언어들 보기
newspaper.languages()
# 특정 뉴스 기사의 url을 통해 기사를 다운로드하고,
# 파싱하며, 기사의 메타데이터와 본문 내용을 추출
from newspaper import Articleurl = 'https://v.daum.net/v/20240624093620484'
article = Article(url, language='ko')# 기사를 다운로드하여 제목과 본문을 파싱하는 작업
article.download()
article.parse()
print('title:',article.title)
print()
print('content:',article.text)
additional_info = [
"※ 기자 김사과(apple@apple.com) 취재 반하나(banana@banana.com)",
"<h2>'핸섬가이즈'가 개봉 전 시사회를 통해 언론과 관객 모두를 사로잡으며 예사롭지 않은 호평을 얻고 있다</h2>",
"이 기사는 임시 데이터임을 알립니다 …",
"Copyright@코리아IT아카데미",
"<br> ☞ 이 기사는 문화 섹션으로 분류되었습니다 … <br>",
"#기사 #문화 #핸섬가이즈 #시사회"
]
context = article.text.split('\n\n')
context += additional_info
context
# context라는 리스트의 각 원소에 대해 인덱스와 함께 출력
for i, text in enumerate(context):
print(i, text)
# 불용어 제거하기
# 불용어 사전 정의 ['※', '☞', '…', '오싹']
# delete_stopwords(): context 데이터를 넣으면 불용어를 제거 후 리스트(데이터)를 반환
stopwords = ['※', '☞', '…', '오싹']
def delete_stopwords(context):
preprocessed_text = []
for text in context:
# 공백을 기준으로 분리된 단어들 중 불용어가 아닌 것만 선택
text = [w for w in text.split(' ') if w not in stopwords]
# 처리된 단어들을 다시 공백을 이용해 문장으로 만들어 리스트에 추가
preprocessed_text.append(' '.join(text))
return preprocessed_text
# 처리된 문장들 출력
preprocessed_context = delete_stopwords(context)
for i, text in enumerate(preprocessed_context):
print(i, text)
# 이메일 제거
# delete_email(): context 데이터를 넣으면 이메일 제거 후 리스트(데이터)를 반환
import re
def delete_email(context):
preprocessed_text = []
for text in context:
# 이메일 패턴을 정규표현식으로 찾아 제거하고, 앞뒤 공백 제거 후 리스트에 추가
text = re.sub('[a-zA-Z0-9+-_.]+@[a-zA-Z0-9]+\.[a-zA-Z0-9]+', '', text).strip()
if text:
preprocessed_text.append(text)
return preprocessed_text
preprocessed_context = delete_email(preprocessed_context)
for i, text in enumerate(preprocessed_context):
print(i, text)
# HTML 태그 제거
# delete_html_tag(): context 데이터를 넣으면 HTML 제거 후 리스트(데이터)를 반환
def delete_html_tag(context):
preprocessed_text = []
# < 태그의 시작을 나타내는 문자를 찾음
# .*? 다음에 오는 패턴과 매칭되지 않을 떄까지 최소한의 문자를 포함
# '.': 줄 바꿈 문자를 제외한 모든 문자
# '*?': 0번 이상 가능한 적게를 의미
html_tag = re.compile('<.*?>')
for text in context:
text = re.sub(html_tag, '', text).strip()
if text:
preprocessed_text.append(text)
return preprocessed_text
preprocessed_context = delete_html_tag(preprocessed_context)
for i, text in enumerate(preprocessed_context):
print(i, text)
# 해시태그 제거
# delete_hashtag(): context 데이터를 넣으면 해시태그 제거 후 리스트(데이터)를 반환
def delete_hashtag(context):
preprocessed_text = []
for text in context:
text = re.sub('#\S+', '', text).strip()
if text:
preprocessed_text.append(text)
return preprocessed_text
preprocessed_context = delete_hashtag(preprocessed_context)
for i, text in enumerate(preprocessed_context):
print(i, text)
# 문장 분리
# 학습 데이터를 구성할 때 입력 데이터의 단위를 설정하기 애매해질 수 있으므로
# 문장 단위로 모델이 학습할 수 있도록 문장 분리가 필요
# 한국어 문장 분리기 중 kss 라이브러리를 사용
!pip install kssimport kss# 문장을 분리하기 위한 함수
def sentence_seperator(context):
splited_context = []
for text in context:
text = text.strip() # 양쪽 공백 제거
if text:
# 문장이 분리됨
splited_text = kss.split_sentences(text)
splited_context.extend(splited_text)
return splited_contextpreprocessed_context = sentence_seperator(preprocessed_context)
for i, text in enumerate(preprocessed_context):
print(i, text)
# 반복 횟수가 많은 문자 정규화
!pip install soynlpfrom soynlp.normalizer import *repeat_normalize('ㅋㅋㅋㅋㅋㅋㅋㅋ', num_repeats=2)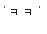
repeat_normalize('야야!!!! 너!!!! 하하하하하.. 지금 뭐하냐? ㅠㅠㅠㅠㅠ', num_repeats=2)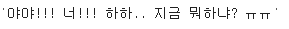
# 중복 문장 정규화
# OrderedDict: 순서가 있는 딕셔너리(Dictionary) 타입
# 기존의 딕셔너리와는 달리 아이템이 추가된 순서를 기억
from collections import OrderedDict# 중복된 문장을 제거하는 함수
def duplicated_sentence_normalizer(context):
context = list(OrderedDict.fromkeys(context))
return contextpreprocessed_context = duplicated_sentence_normalizer(preprocessed_context)
for i, text in enumerate(preprocessed_context):
print(i, text)
# 문장 길이 기반 필터링
# min_max_filter(min_len, max_len, context): min_len 보다 길고, max_len 보다
# 짧은 문장만 필터링하여 저장
def min_max_filter(min_len, max_len, context):
preprocessed_text = []
for text in context:
if min_len <= len(text) and len(text) < max_len:
preprocessed_text.append(text)
return preprocessed_textpreprocessed_context = min_max_filter(20, 200, preprocessed_context) # 20글자 이상 60글자 미만의 문장들만 반환
for i, text in enumerate(preprocessed_context):
print(i, text)
# 토큰화
from tensorflow.keras.preprocessing.text import Tokenizer
# word2idx를 key와 value를 반대로 적요
# {1:'한국영화', 2:'예매율' ... }
idx2word = {value : key for key,value in word2idx.items()}
print(idx2word)
encoded = tokenizer.texts_to_sequences(preprocessed_context)
print(encoded)
vocab_size = len(word2idx) + 1
print(f'단어 사전의 크기: {vocab_size}')
print(encoded[0])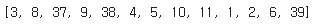
'자연어 처리(NLP)' 카테고리의 다른 글
| 6. Rnn 기초 (0) | 2024.06.21 |
|---|---|
| 5. 워드임베딩 시각화 (0) | 2024.06.21 |
| 4. 워드 임베딩 (1) | 2024.06.17 |
| 3. 임베딩 (0) | 2024.06.17 |
| 1. 자연어 처리 개요(Natural Language Processing) (0) | 2024.06.17 |



