
1. 포켓몬 분류
- Train: https://www.kaggle.com/datasets/thedagger/pokemon-generation-one
- Validation: https://www.kaggle.com/hlrhegemony/pokemon-image-dataset
Pokemon Generation One
Gotta train 'em all!
www.kaggle.com
Complete Pokemon Image Dataset
2,500+ clean labeled images, all official art, for Generations 1 through 8.
www.kaggle.com
# 데이터셋 다운로드
import os
os.environ['KAGGLE_USERNAME'] = 'kwak0318 '
os.environ['KAGGLE_KEY'] = 'dcb13dc724efcf65a915a5d5e8b1d44e'
!kaggle datasets download -d thedagger/pokemon-generation-one
!kaggle datasets download -d hlrhegemony/pokemon-image-dataset
# 압축 해제
!unzip -q pokemon-generation-one.zip
!unzip -q pokemon-image-dataset.zip# 디렉토리 이름 변경하기 - 리눅스 문법으로
!mv dataset train
!rm -rf train/dataset
!mv images validationtrain_labels = os.listdir('train')
print(train_labels)
print(len(train_labels))
val_labels = os.listdir('validation')
print(val_labels)
print(len(val_labels))
# 디렉토리 이름 변경하기 - 파이썬 shutil
import shutil
for val_label in val_labels:
if val_label not in train_labels:
shutil.rmtree(os.path.join('validation', val_label))val_labels = os.listdir('validation')
(len(val_labels))
for train_label in train_labels:
if train_label not in val_labels:
print(train_label)
for train_label in train_labels:
if train_label not in val_labels:
print(train_label)
os.makedirs(os.path.join('validation', train_label), exist_ok=True)
val_labels = os.listdir('validation')
(len(val_labels))
import torch
import torch.nn as nn
import torch.optim as optim
import matplotlib.pyplot as plt
from torchvision import datasets, models, transforms
from torch.utils.data import DataLoader
from torch.nn import functional as Fdevice = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
print(device)
# transforms 만들기
# Compose를 사용하여 사이즈, Affine, RandomHorizontalFlip, ToTensor 역할
data_transforms = {
'train': transforms.Compose([
transforms.Resize([224, 224]),
transforms.RandomAffine(0, shear=10, scale=(0.8 , 1.2)), # 랜덤하게 변경할 것을 선택(인덱스 0번부터 10가지 선택, 크기는 범위 +-20%하여 랜덤하게 변경)
transforms.RandomHorizontalFlip(), # 랜덤하게 이미지 좌우 반전
transforms.ToTensor() # 이미지를 텐서형으로 변환
]),
'validation': transforms.Compose([
transforms.Resize([224, 224]), # 사이즈 맞춤
transforms.ToTensor()
])
}# 데이터셋 만들기
image_datasets = {
'train': datasets.ImageFolder('train', data_transforms['train']), # data 폴더 안에 train 폴더를 데이터셋화
'validation': datasets.ImageFolder('validation', data_transforms['validation'])
}# 데이터로더 만들기
dataloaders ={
'train': DataLoader(
image_datasets['train'],
batch_size=32,
shuffle=True
),
'validation':DataLoader(
image_datasets['validation'],
batch_size=32,
shuffle=False
)
}
print(len(image_datasets['train']), len(image_datasets['validation']))
# 이후 생성된 데이터셋을 transforms 딕셔너리에 적용하여 정제된 train, validation 데이터셋 객체를 만듭니다.
# 그런 다음, 학습에 사용할 Dataloader에 넣어 dataloader 딕셔너리를 구성합니다.
# 이전에 수행했던 과정과 마찬가지로, 학습 시 batch_size를 32로 설정하여 32개씩 학습을 진행합니다.

# 1개의 batch만큼 이미지를 출력
imgs, labels = next(iter(dataloaders['train']))
fig, axes = plt.subplots(4, 8, figsize=(20, 10))
for img, label, ax in zip(imgs, labels, axes.flatten()):
ax.set_title(label.item())
ax.imshow(img.permute(1,2,0)) # 텐서에 저장되어있을 때 shape(컬러, 가로, 세로) -> matplotlib에서는 (가로, 세로, 컬러채널)
ax.axis('off')
# 32개의 이미지가 배치사이즈 32로부터 변환되어 생성됩니다
image_datasets['train'].classes[122]
2. EfficientNet
- 구글의 연구팀이 개발한 이미지 분류, 객체 검출 등 컴퓨터 비전 작업에서 높은 성능을 보여주는 신경망 모델
- 신경망의 깊이, 너비, 해상도를 동시에 확장하는 방법을 통해 효율성과 성능을 극대화한 것이 특징
- EfficientnetB4는 EfficientNet 시리즈의 중간 크기 모델
# 사전 학습된 EfficientNetB4 모델
from torchvision.models import efficientnet_b4, EfficientNet_B4_Weights
from torchvision.models._api import WeightsEnum
from torch.hub import load_state_dict_from_urldef get_state_dict(self, *args, **kwargs):
kwargs.pop("check_hash")
return load_state_dict_from_url(self.url, *args, **kwargs)
WeightsEnum.get_state_dict = get_state_dictmodel = models.efficientnet_b4(weights='IMAGENET1K_V1').to(device)
print(model)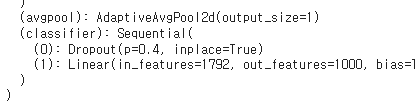
for param in model.parameters():
param.requires_grad = False # 가져온 파라미터(W, b)를 업데이트 하지 않음
# 모델의 FC 레이어이름이 classifier
model.classifier = nn.Sequential(
nn.Linear(1792,512),
nn.ReLU(),
nn.Linear(512,149) # output이 149개
).to(device)
# 이번에 사용할 모델은 EfficientNetB4입니다.
# 그리고 모델을 불러와서 출력 레이어를 수정하여 완성시킬 것입니다.# 학습
# optimizer: Adam
# epochs : 10
optimizer = optim.Adam(model.classifier.parameters(), lr=0.001)
epochs = 10
for epoch in range(epochs):
for phase in ['train', 'validation']: # train과 validation 따로 반복문을 돌아
if phase == 'train':
model.train()
else:
model.eval() # 학습 모드에 있던 메모리를 지우고 바로 Test모드(훨씬 빠름)
sum_losses = 0
sum_accs = 0
# train이라면 train에 대한 데이터로더, validataion이라면 validation에 대한 데이터로더 (따로 쓰지 않고 합쳐서 씀)
for x_batch, y_batch in dataloaders[phase]:
x_batch = x_batch.to(device)
y_batch = y_batch.to(device)
y_pred = model(x_batch)
loss = nn.CrossEntropyLoss()(y_pred, y_batch)
if phase == 'train':
optimizer.zero_grad()
loss.backward()
optimizer.step()
sum_losses = sum_losses + loss
y_prob = nn.Softmax(1)(y_pred)
y_pred_index = torch.argmax(y_prob, axis=1)
acc = (y_batch == y_pred_index).float().sum() / len(y_batch) * 100
sum_accs = sum_accs + acc
avg_loss = sum_losses / len(dataloaders[phase])
avg_acc = sum_accs / len(dataloaders[phase])
print(f'{phase:10s}: Epoch {epoch+1:4d}/{epochs} Loss: {avg_loss:.4f} Accuracy: {avg_acc:.2f}%')
# 데이터 구성 및 모델 수정이 완료되었다면 학습을 시작합니다.
# 이번에는 train 데이터와 validation 데이터를 동시에 학습시켜 보겠습니다.
# 데이터 종류에 따라 모델을 적절히 설정하고 반복문을 실행합니다.
# validation 데이터는 학습 후에 결과를 평가하는 데이터셋이므로,
# train 데이터일 경우에만 optimizer 매개변수를 조정하는 코드를 추가합니다.
# 학습된 모델 파일 저장
torch.save(model.state_dict(), 'model.pth') # mode.h5# 저장된 모델 학습
model = models.efficientnet_b4().to(device)
model.classifier = nn.Sequential(
nn.Linear(1792, 512),
nn.ReLU(),
nn.Linear(512, 149) # output이 149개
).to(device)
print(model)
model.load_state_dict(torch.load('model.pth'))
# 평가모드로 사용
model.eval()
# 테스트(validation에 있는 2종의 포켓몬을 통해 분류테스트)
from PIL import Image
img1 = Image.open('validation/Snorlax/4.jpg')
img2 = Image.open('validation/Diglett/0.jpg')
fig, axes = plt.subplots(1, 2, figsize=(12, 6))
axes[0].imshow(img1)
axes[0].axis('off')
axes[1].imshow(img2)
axes[1].axis('off')
plt.show()
# validation 이미지를 transform(텐서형으로 변환)
# data_transforms의 validation 키의 value 값에 img1을 통과시킴 -> Resize되고 Tensor로 변환
img1_input = data_transforms['validation'](img1)
img2_input = data_transforms['validation'](img2)
print(img1_input.shape)
print(img2_input.shape)
# 두 이미지를 첫번째 차원에 맞춰 하나의 이미지 텐서로 결합
test_batch = torch.stack([img1_input, img2_input])
test_batch = test_batch.to(device)
# 두 개 이미지가 붙음, torch.Size([2, 3, 224, 224]): (2(배치크기), 컬러채널, 세로, 가로)
test_batch.shape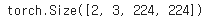
# 예측값 도출
y_pred = model(test_batch)
y_pred
# 예측값에 대한 예측 확률
y_prob = nn.Softmax(1)(y_pred)
y_prob
# 확률이 높은 k개의 데이터 뽑기
# prob이나 가중치가 많을 때 k개만 위에서부터 뽑음 ->
# indices에는 인덱스, probs에는 값이 반환
probs, idx = torch.topk(y_prob, k=3) # 상위 3개
print(probs)
print(idx)
# 예측 결과 시각화
fig, axes = plt.subplots(1, 2, figsize=(15, 6))
axes[0].set_title('{:.2f}% {}, {:.2f}% {}, {:.2f}% {}'.format(
probs[0, 0] * 100,
image_datasets['validation'].classes[idx[0, 0]],
probs[0, 1] * 100,
image_datasets['validation'].classes[idx[0, 1]],
probs[0, 2] * 100,
image_datasets['validation'].classes[idx[0, 2]],
))
axes[0].imshow(img1)
axes[0].axis('off')
axes[1].set_title('{:.2f}% {}, {:.2f}% {}, {:.2f}% {}'.format(
probs[1, 0] * 100,
image_datasets['validation'].classes[idx[1, 0]],
probs[1, 1] * 100,
image_datasets['validation'].classes[idx[1, 1]],
probs[1, 2] * 100,
image_datasets['validation'].classes[idx[1, 2]],
))
axes[1].imshow(img2)
axes[1].axis('off')
'머신러닝 & 딥러닝' 카테고리의 다른 글
| 머신러닝 분류 알고리즘 4가지 정리 (1) | 2025.04.18 |
|---|---|
| 21. 전이 학습 (0) | 2024.06.17 |
| 20. 간단한 CNN 모델 만들기 (0) | 2024.06.17 |
| 19. CNN 기초 (0) | 2024.06.13 |
| 18. 비선형 활성화 함수 (0) | 2024.06.13 |


